AI Memory: Market Dynamics
A comprehensive review (part 3/4)

See part 1 for the pre-history of AI Memory and part 2 for the sector’s technical foundations. Or see the full report here.
Introduction
We just covered a lot, so let’s take a step back. So far, we briefly overviewed the history of “memory” from basic RAG to today’s architectures. Then, we dove deeper into the technical weeds of how to build these systems. We will now re-emerge from this depth and review what memory is practically used for today as well as who is actually providing memory products in the market.
While we kick the can down the road on market sizes, we connect the use cases to providers and ask where exactly the majority of value will accrue in this space.
Section 1: Use Cases
With the exception of some edge cases, the majority of applications and agents requiring memory fall under 3 categories:
B2C – Life Self: the individual is the center. Memory creates personalization and persistence.
B2B2C – Mediated Self: the consumer is the center, but used to provide better core services.
B2B – The organization, system, or process is the center. Often process automation.
It would not be possible to review every use case and implementation of memory, so we will give a high level review and an example for each.
B2C (Consumer)
In consumer applications, the center of gravity is the individual. In these applications, memory may be the product itself or memory may be core to the value proposition. Users demand an application that knows and understands them. In order to build a companion, coach, “second brain,” or a personal assistant, there must be continuity so you aren’t starting from scratch each conversation.
Companions & Therapists: AI that builds a psychological profile to offer emotional support (e.g., remembering trauma or relationship dynamics).
Coaches (Health/Finance): Agents that track longitudinal progress (e.g., “Your spending on takeout has dropped 15% since our talk last Tuesday”).
“Second Brains”: Tools that ingest your entire digital life (emails, notes, reading history) to act as a searchable extension of your mind.
Personal Shoppers: Agents that remember your size, style evolution, and the fact that you hate polyester.
Tutors: Education bots that track your learning curve, remembering exactly which concepts you struggled with three weeks ago.
Example: Kin AI is a personal AI designed to be a supportive peer. Unlike standard chatbots, Kin used a memory architecture called Semantic Spacetime [Kin].
Priority: Most RAG systems are “timeless” and just find matching keywords. Kin treats time and causality as core to memory. If you tell Kin you are nervous about a presentation on Friday, and you log back in on Saturday, it proactively asks, “How did it go?”
The Architecture: It doesn’t just store the text; it stores the event on a temporal graph, linking the “Date” event to your “Anxiety” entity. This allows the AI to “wake up” with an understanding of where you are in your life’s narrative, not just what you last typed.

B2B2C (Business-Consumer)
When memory is built into an existing business, context is used to improve the value of products or services. The culture of different companies and industries are subtly different and the value must be clearly proposed for how it will improve their existing business (i.e. conversions for e-commerce). This is where memory, data density, and clear ROI line up most naturally.
Many companies will use memory as a logical extension of their existing data collection and personalization practices. Others will reimagine them entirely. X has notably begun using LLMs in their recommendation systems, which was seen as heretical to literature published by Twitter’s previous RecSys teams.
Common Use Cases:
Chat Bots/Voice Agents: The new frontier of support. Voice agents require ultra-low latency (sub-300ms) to feel natural. Memory must be retrieved faster than a human can blink.
Dynamic UI/UX: Interfaces that generate themselves on the fly based on user history. Instead of a static website, the AI renders a custom dashboard for you.
Transactional Support: Agents that instantly recall order history and return policies to close tickets without human intervention.
Example: The Enterprise Voice Agent Voice agents have seen some of the most natural value creation, redefining the entire customer support market.
Priority: Latency. A natural conversation has a “turn-taking” gap of ~500ms. If the AI takes 2 seconds to remember who you are, the illusion breaks.
The Architecture: These systems cannot use complex, multi-hop reasoning during the call. They rely on caching and background processing. Before the call connects, the memory system pre-fetches the user’s profile (name, last order, sentiment) and injects it into the immediate context window. The memory architecture is optimized for read-speed (milliseconds) rather than depth.


B2B (Enterprise)
In the enterprise, AI agents are always on, automating ever-larger chunks of the “services” work that powers the global economy. Memory here is about coordination and continuity of work. It is also the difference between an intern who needs to be re-trained every morning and a veteran employee.
Common Use Cases:
Coding Agents: Autonomous developers that navigate complex repositories, remembering dependency trees and architectural decisions.
“Swarm” workflows: Multiple agents coordinating across sales, ops, or support. One agent’s action becomes another’s context.
Back-office automation: Invoices, reconciliations, approvals, escalations—all of which have state that extends beyond a single request.
Example: The “Always-On” Service Agent Consider an AI responsible for reconciling invoices.
Priority: Precision is non-negotiable. A hallucination means financial fraud or audit failure. Logs are required for auditing.
The Architecture: These systems rarely use simple vector search. They rely on strict ontologies. The memory must track the state of a task (e.g., “Waiting for approval from Bob”). It compresses the complexity of 10,000 emails into a single “State” object that the agent can act on reliably.
Hardware / Networks / Miscellaneous
Hardware is becoming a hotbed for new products infused with AI. Devices that see what you see and hear what you hear, pave the way for a future where we can build “proactive AI” and devices that act as support for the human brain’s limitations.
New social networks will be built in which context is the memory link across people, ideas, and organizations. Boardy is an interesting “superconnector” application that connects individuals with similar interests proactively, as you imagine LinkedIn should.
Example: Limitless (Acquired by Meta in December 2025) The recent acquisition of Limitless (formerly Rewind) by Meta represents that “hand off” of human memory to machines. Limitless built a “pendant” that records and transcribes real-world audio.
Priority: Quantity matters. Memory here is a firehose: the core challenge is not retrieval, it’s deciding what to keep, how to compress it, and how not to leak it.
The Architecture: This requires massive audio ingestion and privacy filtering at the edge. The system must process 16 hours of audio a day, identify speakers, and index it all without sending sensitive data to the cloud unnecessarily.
Section 2: Market Providers
We have established there will be many different AI applications requiring memory in different ways. We can think of this as the demand side of memory.
We will now overview the supply side. For developers today, what options are available for building performant AI systems?
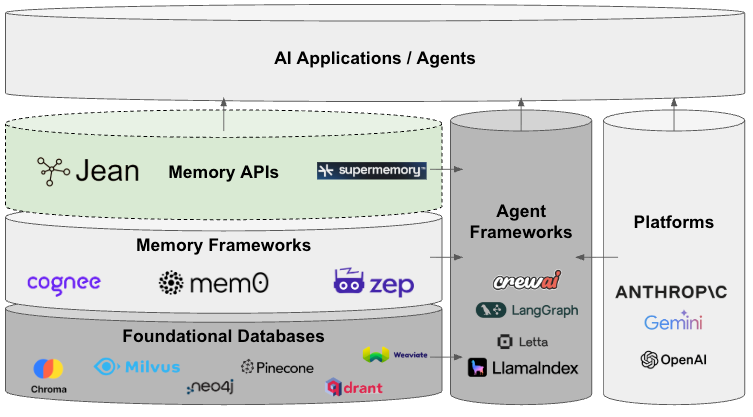
We generally categorize market providers of memory by:
Platforms
Agent Frameworks
The “Memory Stack”
Layer 1: Foundational Databases
Layer 2: Memory Frameworks
Layer 3: Opinionated Memory Products
1. Platforms
The leading platforms providing LLMs have the natural distribution to provide memory services. If we have learned anything from the development of these companies, it is that incumbents shouldn’t be ignored, their capacity to innovate and move fast is unlike previous cycles.
While these companies have each taken a different philosophical approach to how they offer memory to developers, they are general for the most part.
OpenAI
OpenAI’s bet is mostly consumer-first and they are clearly aiming to be the next big “walled garden” of consumer data. If you have used their product, you likely have an intuition for how it works. ChatGPT mostly uses semantic memory to store:
Explicit facts you tell it (“I’m a lawyer in SF”)
Patterns across your chats (topics, projects, preferences)
Recent conversation history and usage metadata.
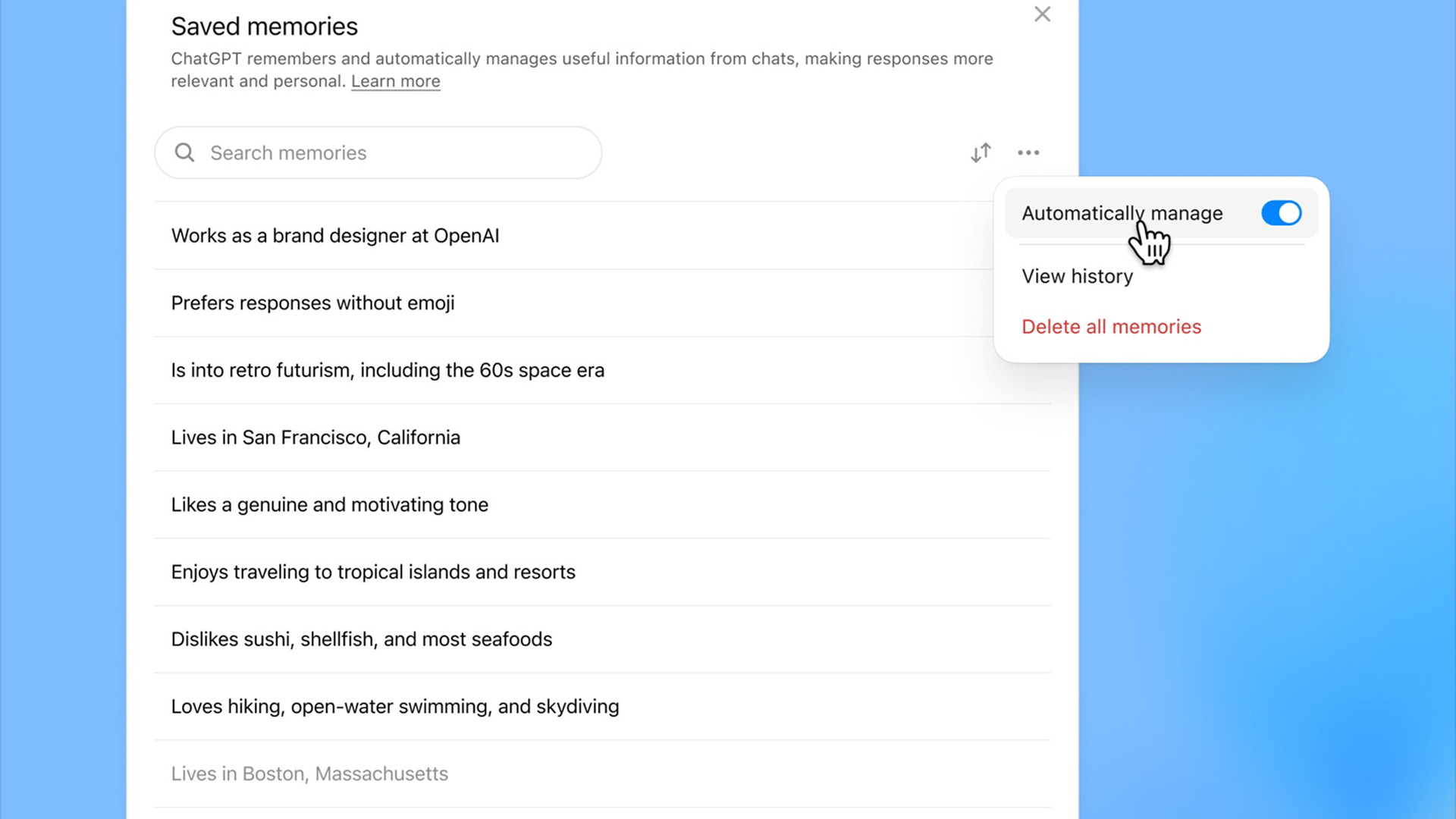
For developers, they’re slowly pushing toward a more stateful API, but it’s still OpenAI’s memory, inside OpenAI’s world. This is a general purpose memory with extreme vendor lock-in.
Anthropic
Anthropic’s Memory SDK, we believe, is a glimpse into the future of what memory systems will look like. Notably, developers have the control to store memory on internal systems. Anthropic is not trying to own this layer.
Here, memory is designed to be relatively task agnostic and is a move towards unified memory. The operations of deciding what to read and write are given to the LLM itself through the model context protocol.
This memory is opinionated, but it is still relatively simple and can not scale to large context tasks. It is notable that this memory is not the same as its consumer memory, and is built for agentic enterprise tasks.
Google Gemini
Google’s bet is managed enterprise memory. Gemini personalizes using your Google data, and in the cloud they offer Vertex AI Memory Bank, a service that extracts and stores “memories” from agent conversations and serves them back via API.
It’s convenient if you’re all-in on Google Cloud, but the memory lives inside Google’s schema and stack, not as a portable asset you can freely shape and move.
Gemini is also building the largest context windows of the bunch. It’s reasonable to assume that over time, increased context windows will eat some memory implementations.
2. Agent Frameworks
For most agent frameworks, memory is not their core value proposition, and you can bring your own external memory stores. These frameworks are built to provide scaffolding for easier development of agent orchestration and development. CrewAI, LangChain, and LlamaIndex compete here.
The exception where memory is core to the agent framework is Letta, a Berkeley spinout initially focused on memory. Letta later shifted gears to compete against frameworks like LangChain. They provide “memory blocks” and other opinionated memory architectures including sleep-time compute.
3. The Memory Stack
The memory stack offers the basic building blocks of databases all the way up to abstract, opinionated memory solutions.
A) Foundational Databases
At the most basic level, you can build memory from the ground up using the building blocks of existing vector and graph databases. These databases may be adding agentic features, but it is already clear that this category is seeing massive commodification.
Vector Databases
Pinecone, Weaviate, Qdrant, Chroma, Milvus
Optimized for similarity search at scale
You own the chunking, embedding model selection, and retrieval logic
Graph Databases
Neo4j, Graphiti (Zep)
Enforce entity-relationship structure
Powerful for bounded domains; brittle for open-ended conversation
B) Memory Frameworks
The middle layer abstracts away the plumbing: de-duplication, timestamping, metadata management, and standard operations like add_memory and search_memory. These are the building blocks that let you assemble a memory system without starting from zero. For the most part, Mem0 has already won this category.
Memory Frameworks
Mem0: Memory layer with built-in entity extraction and conflict resolution. Open-source core with managed offering. Making a bet that companies will reject vendor lock-in.
Zep: Long-term memory for AI assistants. Focuses on graph-based relationships and providing temporal structure to memory. Going downstream a bit and attempting to brand themselves as “context engineering.” Narrowing their focus to certain use cases and arguably becoming an opinionated memory product.
C) Opinionated Memory Products
Opinionated memory works out of the box. Claude’s memory and the platforms would also fall into this category. While at the top of the stack, they do not necessarily need to be abstractions of vector or graph databases. With opinionated products, you lose the control of building your own stack from the ground up but you get the ease of implementation and a product that has been stress-tested widely.
Supermemory was one of the first projects that stumbled into this category after coming up as an indie product to save down bookmarks. They eventually offered a wrapper around a database as a developer tool to abstract away much of the complexity of implementation.
Jean also lives in this category. We initially gained traction building memory across applications for consumers. After being reached out to by developers, we began building opinionated memory products.
Section 3: Developer Choices
Ultimately, the decision of which architecture to implement sits with the developer. They face constraints around time, budget, and how important memory is to their application.
The Naive View
In an ideal world, there’s a single product at the top of the stack that “just works” for every use case. You call an API, memory happens, and you focus on your application.
This is not the world we live in.
As we’ve shown throughout this series, a voice agent requiring sub-300ms latency has fundamentally different memory needs than a coding agent tracking dependency trees. A companion app building psychological profiles over months requires different architecture than a customer service bot recalling order history. The use case dictates the architecture. General-purpose memory is a compromise.
The Real Tradeoffs
Build from scratch (Foundational Databases)
When it makes sense: Your use case is sufficiently unique that no existing solution fits. You have engineering capacity to build and maintain the full pipeline. Memory is your core product differentiator.
The cost: You’re solving chunking strategies, embedding selection, retrieval logic, conflict resolution, temporal handling, and scaling—problems that have already been solved elsewhere. Most teams underestimate the ongoing maintenance burden.
The trajectory: The database layer is commoditizing. Pinecone, Weaviate, Qdrant, Chroma are converging on similar feature sets. Building here means competing on implementation details that will matter less over time.
Buy from platforms (OpenAI, Anthropic, Google)
When it makes sense: Memory is a feature, not your product. You’re already locked into a platform ecosystem. Speed to market and simplicity matters more than architectural control.
The cost: Vendor lock-in. Opacity—you can’t see or modify how memory works under the hood. Architectural mismatch—platform memory is general-purpose by design, optimized for the median use case rather than yours.
The trajectory: Platforms will continue bundling memory as a retention mechanism. The memory itself becomes a moat for them, not for you. Your user data lives in their systems.
Assemble from the stack (Frameworks + APIs)
When it makes sense: You need more control than platforms offer but don’t want to build from zero. Your use case is complex enough that general-purpose memory underperforms but not so unique that nothing in the market applies.
The cost: Integration work. You’re making architectural bets on which layers to own and which to outsource. The frameworks and APIs you choose shape your system’s ceiling.
The trajectory: This is where most serious developers land. The question becomes: which layers do you assemble, and from whom?
The Horizontal vs. Vertical Dimension
The stack we’ve outlined is one axis: abstraction level. Developers don’t have infinite time, resources, and expertise, so they are forced to buy products off the shelf of varying simplicity.
The second axis that is just as important is specificity. After you have decided to purchase a memory product, you need to find the product that is well-suited for your specific use case. The more simple, the less likely there is overlap and the less control you have in building. These vertical solutions are ideal when you can find them. The more unique and specific your use case, the more you will have to go down the stack to find raw building blocks to put together for your use case.
Horizontal memory is general-purpose. It works reasonably well across many use cases but isn’t optimized for any particular one. The frameworks and databases live here. The value proposition is breadth and ease of integration.
Vertical memory is domain-specific. It’s designed for a particular class of problems: voice agents, coding assistants, therapeutic companions, enterprise automation. The value proposition is performance on the specific task.
The honest reality is that the memory space is still early. Vertical memory solutions don’t really exist and products claim generality because they haven’t discovered their natural domain. Over time, we expect specialization just as we saw with vertical AI applications themselves.
Section 4: Where Value Accrues
If databases commoditize downward and platforms consolidate upward, where does value accrue in the memory stack?
We see three defensible positions:
Platform lock-in: OpenAI, Anthropic, and Google will capture value through ecosystem control. If you’re building on ChatGPT, you’ll use ChatGPT memory because it’s frictionless. For most simple use cases, it simply won’t make sense to complicate this decision. However, general solutions are inherently not optimized for any specific use cases.
Vertical depth: Where there are memory solutions that go into high-value, vertical use cases where memory is core to a company’s success, but where current memory products are too general.
Infrastructure primitives: At the framework layer, products like Mem0 that become the “standard” way to handle memory operations, can capture value through developer adoption and ecosystem effects. Large enterprises foot the bill to build their own systems.
The middle ground, general-purpose memory APIs that don’t have inherent distribution advantages, aren’t deep enough to be vertical, and aren’t standard enough to be infrastructure, is the most contested and most questionable position.
Conclusion
Memory is not a solved problem. The space is fragmented because use cases are fragmented, and we expect this to accelerate. The companies that win will be those that provide high-value, performant memory that is not commoditized.
For developers: start with your use case, not your database. Understand what outcome you would like to see memory provide for your specific application. Then work backward to the product that delivers it.
—
Part 3 of a 4 part series on AI memory.
If you are interested in implementing memory systems, reach out to Jean.
— jonathan@jeanmemory.com
Good write up Jonathan!