General Personal Embeddings
A trusted infrastructure for the age of AI

Introduction
"For I dipped into the future, far as human eye could see,
Saw the vision of the world, and all the wonder that would be."
- Alfred, Lord Tennyson
We are living in a backward moment of history. We have mapped the complexity of so much of the universe, seas, worldly information, and created an intelligence approaching our own, yet we still don’t understand ourselves. This is a singular moment in history where this will be corrected.
The last decade has been important for humanity. Machines now understand the world through text. Read that again. Since text is often a projection of the human mind, machines understand us.
Understanding the mechanics of how this technology works is important. In many ways, vector embeddings, representation learning, and interpretability are the most misunderstood and underappreciated developments in the intelligence age.
It is clear there will be thousands of emerging applications that require personal embeddings. In order for the industry to reach its potential, proper infrastructure straddling safety, security, the curse of dimensionality, no free lunch theorem, and the bitter lesson is required.
The future is not predestined and this infrastructure can take many forms. It will take careful guidance to shape a world where individuals own their data, rather than a perverse future where our data owns us.
I make the argument for a universal, trusted, neutral, 3rd-party software where no individual parties own human embeddings, and can safely and securely plug into any AI application for easy use.
Thesis
In this essay, I argue that deep representation learning has unlocked the ability to map the complexity of the human mind into computational space. Through the use of vector embeddings, we can enhance self-understanding and create AI applications that interact with us on a profoundly personal level. However, to guide this technology responsibly, we must establish a universal, trusted, and neutral third-party infrastructure that safeguards individual data ownership and privacy, ensuring we own our data rather than our data owning us.
Chapter 1 - Chess as an Analog to Human Instinct
The Beauty of Chess
Chess is a beautiful game, and it was my first fixation. It wasn’t my family’s first connection to chess. Here’s a game where José Raúl Capablanca, then Cuban Chess Champion of the world, plays my great-great grandfather Jaime Baca-Arús blindfolded.
Different players have different styles, there are many ways to win. Capablanca was known for his endgame. He could convert small advantages into wins with perfection. Most of my peers in the chess community play in similar fashion. It is said that because chess is too complex for the human mind, you should let the other player make a mistake, go up a pawn early, secure a slight positional advantage, trade your pieces, and conservatively guide the game to victory or draw.
I always hated these games and found them extremely boring. In chess, I am an aggressive and intuitive player. To me, the most inspiring chess player of all time is Mikhail Tal, who also took the world title, but with a completely different strategy.
Overcoming Complexity
Rather than focusing on simplicity and precision, Tal used complexity to his advantage and would purposefully venture into dangerous positions, often psychologically tormenting even the most seasoned grandmasters with valiant sacrifices. He is quoted:
“You must take your opponent into a deep dark forest where 2+2=5, and the path leading out is only wide enough for one.”
No one in their right mind would consider the below Queen sacrifice (Bobotsov vs Tal) sane. But Tal wins decisively.
Human Intuition
What is it about Tal? Many players can feel potential opportunities. We all have raw human instincts, where our gut tells us there’s an opportunity or risk, but our mind can’t quite pin it down, or we can’t map the future far enough. Since we can’t map the future far enough, we see it no more sound than a flip of a coin. We leave fate up to chance.
Both Tal and his opponent saw these lines, but even in a highly analytical arena like chess, Tal trusts his own instincts in the face of uncertainty. That’s what makes Tal heroic.
Where Capablanca converts likely wins, Tal makes unlikely, ingenious moves. Where Capablanca is simple, Tal is volatile. Where Capablanca follows strict theory, Tal rips cigarettes, drinks heavily, and invents new chess on the spot.


Computer Intuition
Humans were blown away by the success of chess engines. They make unlikely moves that are consistently better than us. Like Tal, they thrive in highly complex environments, but they do so with the precision of Capablanca, making them unstoppable.
The reason for this is computers are built to map complexity with precision. Think like calculators.
Chess is a Narrow Game
Computers excel in chess because the problem set is narrow enough that they can map most of it out. Chess is a pretty limited and determinate game. There are many possible positions, but there are 32 pieces, the board is 2-dimensional, and there are only 64 squares.
These models are not generally intelligent, which is an important aspect of intelligence. A machine learning model’s ability to generalize is the ability to perform well with data that it has not yet seen. These chess engines are trained narrowly and are not able to generalize across the complexity of all life’s domains. We saw deep learning models that were trained to identify numbers or pictures of dogs as well as humans. While this is impressive, you wouldn’t want to ask that same model for a stock recommendation.
This phenomena is due to the machine learning principle "No Free Lunch Theorem" (NFLT). The No Free Lunch Theorem states that, when averaged over all possible problems, no one algorithm performs better than any other. In other words, with limited training resources, a machine learning model that is trained on one narrow task performs better than a generally trained model on that task. That makes sense.
Life is Broader and More Complex
Life is much more complex than chess. Even in the narrow game of chess, people shy away from complexity and opt for the simple methods of Capablanca. In life, this is also true. The vast majority of people today prefer simple paths to complex paths.
You can find success in life by making likely, determinate, and simple decisions consistently. Go to a good school, ride the path, get a good job, invest your 401(k) into value stocks, compound at 10%.
But I’d also argue that greater complexity in the real world enables many more interesting, novel, non-linear, creative, and valuable decisions if it is overcome. In a world where we have so many 20 year-old multi-millionaires and billionaires, other people have found better ways, therefore they can be found, therefore you can find them.
My stance is clear. Reverence for current systems is valuable, but there is too much of it in the world today (Launching Irreverent Capital).
Humans Have Valuable Instincts, If We Trust Them
Everyone agrees it is possible to achieve great things–just as chess players agree that complex lines may be winning. However, they see these paths as risky, unclear, and up to chance. There’s not enough data on them and they don’t fit into their framework of the world.
The steelman argument for simplicity is the same as in chess. While we are smarter than narrow chess engines, our mind is limited and unable to put up a fight against our much more complex world.
The argument against simplicity is that everyone else faces the same complexity. Cloudy paths don’t mean there’s nothing at the end, they just require more faith. I would argue further that because the complex paths are less traveled, they are wide open. Look around you. No one is taking shots on goal.
Tal trusts his instincts, and he becomes the youngest world chess champion at 23 years old in doing so.
The Problem is Too Much Complexity
The main reason people don’t trust their own instincts is that the world is too complex and they feel they have too little data.
However, the cloudy signal or tug you sense about a particular idea or problem has real value and should be identified at the minimum. George Soros notably invested based on “animal instincts,” then vetted after.
My experience is these little tugs grow into profound realizations that become core to one's identity and understanding of the world. Only after you’ve seen seeds become trees, do you start watering them. Let us cultivate our garden.
We Struggle to Understand Ourselves
While many day-to-day decisions are complex, most of human difficulty is in understanding their own minds. Self-understanding has long been one of the sharpest pain points of the human condition.
Socrates tells us,
“to know thyself is the beginning of wisdom.”
Pascal tells us,
“All of humanity's problems stem from man's inability to sit quietly in a room alone.”
Do You Truly Understand Yourself?
Why do you do the things you do? In 2023, I ran an experiment and asked similar questions to ~50 of my friends. Probing deeper into these questions reveals damning evidence that few actually know why we do anything, including myself.
Why do you want that job?
Why do you want money?
What path are you chasing?
Why do you like that song?
What are your 10-year ambitions?
Why is it that you like that person?
What is it your phobias stem from?
What is it you will regret at the end of your life?
Complexity Leads to Lack of Understanding
Why do you want money? What does it represent or enable? Can you achieve that through another more direct means?
The problem we face isn’t lack of money, resources, friendship, or anything else. Nearly all of man’s problems stem from lack of understanding the self. If you truly understood yourself, you would make very different decisions.
“Why” questions can be difficult to answer, because they are often overdetermined. The person asking the question expects one answer, but there may be thousands of equal weighting. Consider the two questions.
Why do people sleep in a bed?
Why is there conflict in the middle east?
These questions have different levels of complexity. Most people can come to some agreement on the utility of the bed in the first, but the second has proven quite problematic.
I strongly believe that human focus is the most misallocated resource on planet earth. If we can more efficiently unpack ourselves, we can allocate our focus more efficiently.
We Can Use Technology to Understand The World
For the reasons that I will explore throughout this essay, I argue that this is one of the most important problems every human on earth faces and that the present is the first moment in history that we can use technology to solve it.
Deep learning has progressed from recognizing patterns in digits to mastering complex games like chess. We are now approaching a stage where AI can model aspects of the world's complexity and, by extension, provide insights into the patterns of human thought as expressed through data
The next chapter explains the mechanics of how AI maps complexity into vector embeddings.
Chapter 2 - AI and Embeddings
AI Understands Concepts and the Fabric of Reality
In order to prove that now is the singular moment where technology can solve this problem, I first need to overview the current state of AI and embeddings. My answer to the question of what I believe to be true that very few people agree with me on is:
In a world where people have an almost ape-like entrancement with Chat-GPT’s transformer-based next-word prediction, deep representation learning was the real breakthrough in AI.
Transformer-enabled next-word prediction is powerful, but deep representation learning is the foundation that sprung Chat-GPT in the first place. I would argue we will have many important applications of dense embedding space outside of natural language processing.

AI Understands The World and Human Mind Through Language
Deep representation learning downloaded the entire internet and all of its data. By mapping the data in relation to each other in computation space, the models learned language. Since language is a representation of the world and the mind, these models now understand the physical world and the human mind, just as we do.
This is a very important point. Many of the document automation tools, agentic workflows, and other low hanging fruit enabled by OpenAI’s API are mostly an extension of 2000s software. In 2025, we are entering the intelligence age. People will need to start thinking bigger.
Vector Mechanics
It is really important to break down how this intuitively works. Computers understand the world through concepts, just as we do.
You need to embed concepts, such as words, documents, images, etc. into vector embeddings. These embeddings are learned models of concepts in relation to others. The famous example is that when you run King + Woman - Man, the model outputs an approximation of Queen. This video is the best on the subject.
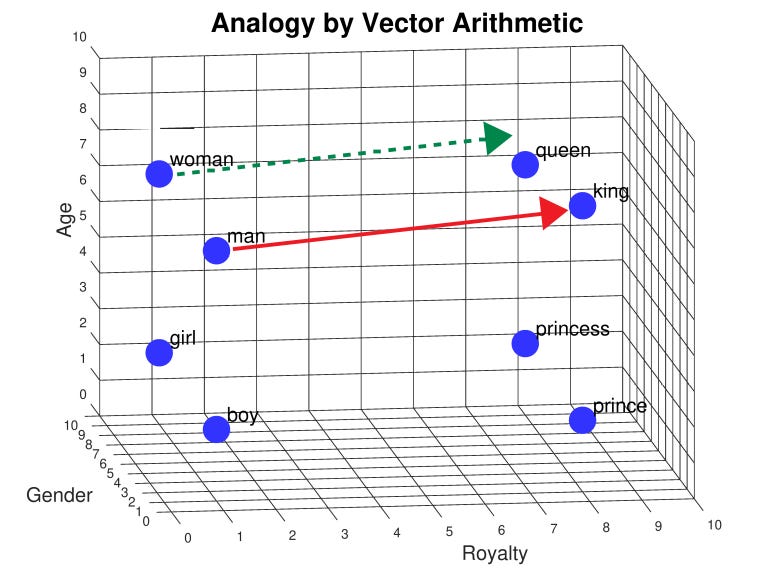
Vectors Turn Data Into Math
These vectors are a string of numbers. Each number represents a distance in a particular direction. The picture above is 3-dimensional to simply represent how the computer may have different axes as different characteristics of the concept.
A 3-dimensional vector would be represented as something like [0.40, 0.08, 0.34]. Where each number represents a direction on the x, y, and z axis. For example, these axes could represent the nation, leader, and time in history that we see above.
The Models Are Becoming More Nuanced
When I ask you to find the answer to King - Man + Woman, you can probably figure it out. You have an idea of the individual characteristics of each. These words are not too abstract so it’s pretty easy. Maybe you can think of some of the above features like Royalty, Masculinity, etc.
Embedding models are more nuanced. They can capture 1,000+ dynamic characteristics related to the specific context in which the word is used. In many ways, machine learning models are already able to understand semantic complexity better than humans.

Abstract Concepts
What is more complex is each of these concepts are represented by smaller concepts that are then represented by smaller concepts. As nuance improves, this complexity is captured better. Embeddings are used to capture the semantic meaning of entire documents today.
The models improving represent better representation of concepts, taking abstract concepts and breaking them down into their components (prior essay: Abstraction vs First Principles). One imagines the concepts becoming increasingly atomic.

Model Improvement (Deep Learning’s Future)
These models are improving exponentially. The big tech companies are spending $10s of billions mapping out the universe with all the computational power, data, and talent they can get their hands on. No one really knows if or when the scaling will start hitting a wall.

Soon, this embedding model will have a better understanding of reality than humans. Like in chess. The Bitter Lesson teaches us that general methods leveraging computation outperform (narrow) domain-specific approaches over time.
In other words, the model will have an extremely complex understanding of the world and where concepts like “King”, “Queen”, “Palace”, or “Chess” embed in that model.
The Curse of Dimensionality
The big limiting factor to this dynamic is that by distilling data into ~1,000 dimensions, you are losing granularity in the features. But if you embed the data into many more dimensions, the data becomes increasingly difficult to work with as points become too sparse in high-dimensional space. The greater the number of dimensions, the volume of embedding space grows exponentially, leading to increasingly sparse data points.
For instance, if you embed a picture of a dog in a large general embedding model, you will have a general understanding of the dog you are embedding, but if you embed that dog in a narrowly trained embedding model on only classifying dog pictures with the background NFLT assumption, the features of that embedding will be much more useful in the classification process.
So there is a balance you must strike in the use of extremely complex generalized embedding models and narrow embedding models for your use case. Notably, Voyage AI has developed a series of narrower embedding models that are cheaper and more effective than their larger peers. I also had the pleasure of seeing Tengyu Ma speak at Simons Institute for the Theory of Computing and it’s clear how innovative this work is.
Interpretability
Another important research area that gets too little attention is interpretability. Researchers I’ve spoken with recognize the important change that interpretability will bring.
While the above example is helpful, the high-dimensional embedding models we have today “self-teach” relationships between words and concepts, so most of the features will be completely alien and unable to be understood when translated into human language.
There is a lot of great open-sourced research coming out of Anthropic (Scaling Monosemanticity) and OpenAI (Extracting Concepts from GPT-4) on the use of sparse autoencoders (SAEs) and Dictionary Learning to cut down feature sets and determine the specific, singular meaning of a feature that activates.
A simple example is in this 2023 Anthropic Paper, Towards Monosemanticity, where the research team successfully extracted interpretable features. In the example below, we see that when you spike the activation level of the “DNA” feature, text starts turning into genetic code.
Similarly, we could imagine running a piece of text through an engine, such as this essay, to extract the millions of features within and their levels of activation, providing an extremely comprehensive fingerprint for use in applications such as similarity search or mapping complexity of concepts in a way that is interpretable (i.e. distilling the major differences between two philosophical arguments and then comparing them to find axes of agreement and disagreement).

Conclusion – We Can Map Complexity With Embeddings
To conclude this chapter on vector embeddings, we have established that vector embeddings can map any concept with increasing complexity and nuance, noting the tradeoff in dimensionality.
As these models scale exponentially, it logically follows that:
Vector embeddings will be able to represent any concept
These vector embeddings will become interpretable
This isn’t just some nerdy fixation. I have plenty of those. In the next Chapter, I will make the assertion that if the above premise is true, we will be able to map out the complexity of our minds into embedding space and interpret it for use across many emerging applications.
Chapter 3 - Mapping Complexity of the Mind
We have established that the world is very complex and computers deal with complexity with precision. In the second chapter, we made the claim that since machine learning models understand language, and language is a representation of the world and a projection of our mind, these models understand the world. We overview how these models understand and interpret any complex concept through vector embeddings.
If these statements are true, what are the implications? Let’s take a look at the psychological angle of how humans understand the world.
How Humans Understand Concepts
We are terrible with complexity in the simplest of games such as chess. In the much more complex world we live in, we are horrific.
When I show you a picture of this dog, the neurons in your brain fire in a similar way that neural networks function. Different neural pathways fire that recognize ears, fur, etc, combined into a representation of a dog.
You visibly see a dog, but that representation hinges on the firing of more than 10 billion neurons per second representing features as atomic as angles and edges that our brain intuitively recognizes.


Understanding This Essay
If you break this essay into individual chapters, paragraphs, words, etc., you start breaking down these concepts into smaller ideas that are composed of smaller ideas.
Something like the following would be the main ideas from the first 3 chapters so far:
The world is complex, like chess, and humans have valuable instincts that they don’t trust
Vector embeddings enable us to map this complexity
We can use these mechanics to map the complexity of the world and our minds
In theory and practice, you can embed this entire essay, each chapter, paragraph, sentence, or word into a vector embedding that represents the underlying concept’s “meaning”.
The Psychology of Cathexis
Cathexis was popularized by Sigmund Freud as the “investment of mental or emotional energy in a person, object, or idea.” This libidinal pull is something like a human instinct.
There is an emotional feeling that you have when you see a picture of a dog. If you’re like me, you love dogs. But I don’t like cats. Why would there be different cathexes for each? They are both similar domesticated animals.
The Breakdown of Cathexis
In the Metaphysical Precepts of Object Cathexes, Sam Schapiro writes,
“Given an object, it is by means of abstracting it into isolated qualities and representing it as such that we can cogitate anything about it at all. An object cathexis, despite being made at the level of representation, makes itself known as an impulse in the sphere of raw sensation. In this phenomenon frequent confusion arises, due to misconstruing the desire for isolated qualities with the desire for the object itself.”
What Sam is saying is that we shouldn’t be confused about what we really love about dogs. We don’t love “dogs.” There are individual characteristics of dogs that we hold strong positive cathexes for.
When the synapses of your brain that represent different features of the dog fire, they may have high activations regarding “cute” or “loyalty” or “companion.” There may also be some like “dirty” that we hold disgust for but are overridden by our stronger love for other characteristics. What if the dog bites your kid? The underlying representation changes.
This misunderstanding is also the same cloudy judgment that causes many of human’s problems in chess and in life. If we can properly map it out, we can understand the exact features we have cathexes towards and more efficiently allocate the most scarce resource that is human focus on things that matter. What you may need is companionship. Dogs may be the indirect way to reach emotional homeostasis.
If we understand that we really want money so that we can afford to retire and do pottery, we may decide on the spot to quit our accounting job and become a pottery instructor.

This image elicits a different emotion that proves our brains don’t register all “dogs” the same.
Optimization Function
The better I understand machine learning, the better I understand humans. We are optimization functions. Humans are unfortunately very transactional in that sense. I personally would like to believe in Immanuel Kant’s world where we see other humans as ends in themselves.
Our brains have an internal embedding space that represents every concept we know, such as different dogs or people. The billions of weights are learned based on a defined optimization function.
A question that I think is quite revealing about a person is “what are you optimizing for?” I don’t think it is a coincidence that this is basically asking “why?”
We don’t know why we do anything because the optimization function of our brain is too complex. I think Nietzsche was correct in saying that:
“He who has a why to live can bear almost any how.”
Most people just need to get the “why” part of their optimization function sorted out.

86 billion neurons in the human brain converging on their optimized weights.
What Are You Optimizing For?
We don’t have great answers to this question. Different people are optimizing for different things. Even individuals likely have multiple optimization functions running concurrently or the function changes over time.
First, you are optimized to not die, homeostasis, and then you proceed to other goals in the over simplistic lens of Maslow’s Hierarchy of Needs. From an evolutionary perspective, after you have satisfied individual goals, you may move on to preservation of the species.
However, you always view your current state in relative terms. Who are you comparing yourself to? Many people end up keeping up with the Jones’ and subliminally absorbing others optimization functions in a very Girardian mimetic sense. We should recognize we all have different optimization functions. At this point in my life, I just want to solve important societal problems.
Mapping The Brain Through Data
With enough data on a person, and the right context, we can map a human being in embedding space. Interestingly, in the world today, there is quite a bit of available data to us. Especially if you write, as I do. This written data is a projection of your mind and thoughts.
In theory, by embedding all of a human’s data, we can approximate the brain of any person. There are some philosophical questions on how close you get and if there are better ways to do so, but you can indeed approximate it, and many companies do some form of this on their user data today.
There are companies today that are also going beyond just data collected through software and actually mapping the brain’s neurons.
Narrow Twitter Data Example
Take the example of a narrow vector embedding capturing the data from just your twitter activity. Obviously, this would actually be around 1,000 features. Ideally, you would try to extract features that are relevant to your platform. A general embedding would capture how your tweets relate to the general representation model of the world.
[0.73, 0.25, -0.55, 0.89, 0.13, 0.67, -0.44, 0.95, -0.23, 0.47]
0.73: Could represent your interest in technology.
0.25: Could reflect the amount of interaction with influential accounts.
-0.55: Could capture the sentiment of your tweets (leaning slightly negative).
0.89: Could represent the frequency of retweets.
0.13: Could reflect the time of day you're most active.
0.67: Could indicate your level of engagement with trending hashtags.
-0.44: Could represent your tendency to engage in controversial topics (leaning toward avoiding them).
0.95: Could indicate a high level of emoji and media usage.
-0.23: Could reflect a decline in activity over time.
0.47: Could capture your general interaction with positive-sentiment content.
The Genetic Analogy
The best heuristic to think about this mapping is likely that of genetic code. Instead of nitrogenous bases that compose alleles of genetic characteristics, you have features of varying numeric weights.

In a sufficiently complex and high-dimensional embedding space that maps the world, you can approximate the brain of a human being. By “embedding” a human being, you can capture their unique characteristics, such as how they respond to certain stimuli, their interest in technology, and quite literally any other possible characteristic.
It is important to note that mapping a person on a large embedding model will lose the nuance that may be helpful on the application but will be generally helpful.
Today We Can Map The Complexity of Our Minds
It is confirmed we can approximate the complexity of a person, which can be both utopian and dystopian, depending on how this is used. In some ways, this isn’t news. Ads companies have been doing this for a long time.
However, ads companies and other applications do this in the narrow sense, like chess. In a future we are entering where the gigantic foundational models understand the entirety of a person, that changes the game, potential applications, and how we should approach the problem.
Chapter 4 - Applications
Current and Future Use of Embeddings
Embeddings aren’t that new and are actually a pretty common tool in software companies’ arsenals. In order to target ads, analyze/predict user behavior, or provide a personalized experience, a company often creates models of behavior and embeds a user in it.
Because embeddings are still black box and not interpretable, use cases remain mostly similarity search where they provide similar products or match you with similar people.
However, I believe that when these embeddings become interpretable, it will open up a slew of new possibilities. Some that we cannot even imagine today.
Simple Examples Used Today
Dating Apps
A simple example of this is dating apps. You input your profile and bio. The machine learning model learns your behaviors and preferences by your actions in the app.
The app rounds up all of this data and embeds it into a vector embedding. Then it conducts a similarity search on profiles that could be a good match for you.
Social Networks
Conduct similarity searches based on your user data to find people who may be good friend recommendations.
Google Search
Rather than older forms of indexing page names, Google is now mostly used as a form of semantic search. This more accurately captures the information you are seeking.
Newer AI Examples
Mercor AI
Mercor just raised $30 million to change the way hiring processes are run. Instead of inefficient processes where recruiters have to find people and then you have poorly run interviews, Mercor takes a different angle.
When you join the site, you upload your resume and do a video interview. The results of these are embedded to create a fingerprint of your applicant profile. On the other side of this 2-sided internal marketplace, you embed job postings.
Now, when you create a profile, it matches up to the job posting that best matches you as a candidate. Cutting away all the inefficient extra steps and increasing efficiency in the global workforce.
Interpretable Use Cases
There will be many other use cases that arrive in the near term when these become more interpretable. I am especially sure of this because I needed this technology to exist to make the following projects. Many more use cases will present themselves in the years to come.
After spending some time at Stanford Law School, I found that there are many opportunities just in the legal sphere.
Problem: Law is an industry built around disagreement. This brings out the worst in people. Simple disagreements between parties in mediations can escalate, leading to millions in avoidable legal costs.
Solution: Mariko is a background filter on communication that detects if an email or zoom conversation is escalating and steers the person communicating back on track.
In addition to case documents, this tool can intake a vector embedding of your character. “Many social and legal conflicts hinge on semantic disagreements.” By having a fingerprint of how you view the world, we can also see your blind spots and guide your conversation with them in mind. We can use AI to make us more human.
Legal Argument Disambiguation
It is clear that there will be more applications in the legal context. Since law is a lot of semantic wrestling, there will be applications that can disambiguate arguments better than we can.
Once disambiguated, they can determine common ground and define areas of disagreement. Defining disagreement is the most important part. There are now ways to toggle writing along certain dimensions to facilitate lower friction negotiations. There are many innovations incoming for how contracts are formed and resolved.
I recently built this project for writers to better understand themselves. Of all the data exhaust we have on all of these platforms, our written data is the deepest and truly is an intimate projection of the mind. I can log my own beliefs in words and then use LLM machinery to tell me exactly how they differ from others or even how they have changed over time, providing me with the fingerprint of my personality. The performance of such techniques will drastically outperform personality tests and especially the astrologists.
There will be emerging tools for writing that interact with ideas and concepts in new ways. Much of this will require a deep understanding of the person writing.
This struck me when I first read the interpretability research coming out of Anthropic, and it became even more clear after I saw Sam Altman emphasize it here and Paul Graham call out the importance of this essay on Writer Detection With LLM Latent Space Images.
Conference Networking (random)
I was in a coffee shop in Hayes Valley and coincidentally met 2 founders who were building an AR/VR application that required personal embeddings. The reality glasses would highlight people highly relevant to you or with overlapping interests/similar vector embeddings.
This just stands as proof that our imagination will be stretched from the many creative applications that will spring from this technology.
Current Market Gap
In order to create any of these applications, you need a representation of a person, or an embedding of them. For Mercor, you need to embed a person to find similar jobs. In the dating sense, you find embeddings to find good matches.
For next-generation interpretable techniques, you will need a comprehensive vector embedding of your data, which is a projection of your mind. By extracting features, you can define your mind in a way that is interpretable to humans. Interpretable methods can also aid human-computer and human-human interaction, such as in Sam Altman’s call for writing tools or my call for Mariko AI in dispute resolution.
Embeddings are not the only method to represent a person, but I argue that in the long-run it will be the most practical and best solution.
Opposing Techniques
There are several alternative approaches to using vector embeddings for human-AI personalization. Each has its strengths and weaknesses, depending on the use case.
Fine-Tuning Based on User Data: This approach customizes a pre-trained model for an individual by retraining it on their data.
Pros: Offers deep personalization and improved performance on specific tasks.
Cons: Computationally expensive and prone to overfitting, limiting generalization.
Large Context Window for Inference: User data is fed into the model’s context window during inference for real-time adaptation.
Pros: Provides live, contextually aware responses without retraining.
Cons: Limited by the context window size and lacks long-term memory persistence.
Retrieval-Augmented Generation (RAG): Combines embedding-based retrieval with generation by accessing stored user data for relevant context.
Pros: Scalable and efficient, offering context-aware personalization.
Cons: Requires complex retrieval systems, with potential for lost nuances in retrieved data.
Single Person Embedding:
Pros: Provides a complete, unified view of an individual, allowing for deep personalization and efficient comparison with others.
Cons: Can lose granularity, making it hard to capture subtle, detailed aspects of behavior. Complex to maintain as new data is added.
These approaches balance customization, resource intensity, and scalability based on the needs of the application. The major drawback of embeddings is that they lose granularity. This is still an area of research for me, but there may be a way to use both narrow embeddings generated for the platform and general embeddings to capture the full picture of a person.
Some models use multilevel or hierarchical embeddings to capture different layers of information. For example, one embedding could capture high-level features, while another captures fine-grained details. This way, you maintain efficiency while still capturing more complex aspects of the data. We may see other embedding techniques such as dynamic/adaptive dimensionality, sparse, and personalized dimensions.
Current Narrow Embeddings
Each company currently has their own tailored, narrow, point solution models, like chess engines. They embed a narrow fingerprint of a person in these models.
In addition to being too limited, they are redundant. Every company is forced to create siloed, unique versions of these embeddings. Often, this creates a barrier to entry and reduces the amount of useful companies that are present in the world today.
Back to the genetic code analogy for human characteristics, we can think of each company generating individual alleles specific to their application. This process is inherently flawed, limited, and overfit to the narrow use case.
The Potential for General Embeddings
While over time, we can predict that general methods that use computation will best map a person generally, there may be methods to use a combination of both general models and narrow solutions. This is something I am watching closely.
These general methods are the state-of-the-art embedding models that already exist.

A Better Method
We can solve this problem at scale by developing a “universal person embedding” representing a person’s “identity genetic code.” This embedding would capture the entirety of a person. Instead of only relying on models of behavior in-house, these companies should be able to get a more comprehensive view of a person and focus on the features (alleles) that are valuable to their use case. This scaled embedding will be much more comprehensive and improve the company’s usefulness while also reducing their corporate overhead.
Regardless, the first step is to create a data vault that connects all of a person’s data across platforms (Spotify, Instagram, SMS, Email, Substack, etc.) and distills it into unified, general embeddings.
With Great Power Comes Great Responsibility
What kind of world do we want to create for ourselves and the next generation? The last 25 years have been a world where large technology companies own us through our captured data.
The world does not need to be that way. As a society, we should choose to own our data and not let the larger companies own us.
Conclusion
There are many emerging AI applications. Each of which require a personalized vector embedding that represents our identity. These applications are forced to create these in isolation.
Data will need to be aggregated in a single place. The past has been a history where large companies have owned our data.
In the next chapter, I will propose a better future. One that needs to be pioneered. One where people own their data in a safe, secure way, but where data is still accessible to AI applications of the future.
Chapter 5 - Middleware for Personal Vector Embeddings
It seems that this is the future we are entering. Someone will make this technology. This technology is also a double-edged sword and one that can deliver us to utopia or dystopia.
Data Safety and Security
The proper framing of this problem is crucial for how we approach this problem legally and philosophically. The embedding of our data is a mapping of our minds, not just predictive exhaust data. Consider this article on California’s view of data safety and security.
“Tech companies collect brain data that could be used to infer our thoughts—so it’s vital we get legal protections right.”
“The new bill amends the California Consumer Privacy Act of 2018, which grants consumers rights over personal information that is collected by businesses.”
Needed Solution
In order to create a future where our data is connected, secure, useful, and owned by the users themselves, it will require a “Datavant-eque Middleware Model for Personal Embeddings.” This solution will need to be made by a company that is:
Ubiquitous
Trusted 3rd Party
Secure, Safe, and de-identified or irreversible
Ubiquitous
By being ubiquitous, you ensure that your embeddings are interoperable and standard throughout the industry. Everyone knows how to interact with your platform and it is cross-compatible, making it a sticky, multi-sided network.
Trusted 3rd Party
You need to be a trusted party in the sense that a company can trust you with their data. By removing yourself from having a stake, you eliminate conflicts of interests with other parties or companies who may feed into the overall data pool.
By being a 3rd party, you enable yourself to be the neutral “Switzerland” in the data collection process. You are recognized as friendly.
Secure, Safe, and Deidentified
In order for companies to be willing to share their data, the sell has to be from a position of strength:
We have a better personal embedding than them so there’s little value in investing in personal systems
Our personal embeddings will be standardized and interoperable
Their data will not be accessible by others in our platform. Embeddings will not be reversible.
There is no risk of liability in our platform
At Shaper Capital, I learned how to connect siloed data and the playbook for creating a Network Business, Scaling Company Culture. When Datavant launched, they had a similar thesis to AI applications, which is “
“We expect hundreds (if not thousands) of healthcare analytics companies will emerge over the next decade, and we expect many to be successful at reimagining key parts of healthcare. Our strategy is to build an open tent.”
I anticipate the same will be the case for personal vector embeddings. Many applications will require embeddings to function. We will build the solid, trusted shoulders in which the future will stand upon.
Why Doesn’t This Exist?
Why now? Why doesn’t this exist? Most companies have valuable data that they don’t want to share. There are also GDPR regulations to protect consumers. Some companies do data co-ops to share data so that each side of the deal has a more comprehensive view of their user.
Why doesn’t this exist at scale?
The two main reasons are:
Companies treat their data as a competitive advantage
If you create the solution in a way that makes the data sharing a win-win, you eliminate the first problem.
Regulations on how companies can collect, store, and share user data
If you create this so that this data is standardized, interoperable, and shareable, without sacrificing confidentiality, you eliminate the second problem.
The Sale Leaseback Analogy
Many non-real estate companies need to have properties for operations. This is outside of their core business and a burden.
Lease Sale-Back Analogy
A leaseback is an arrangement in which the company that sells an asset can lease back that same asset from the purchaser. With a leaseback—also called a sale-leaseback—the details of the arrangement, such as the lease payments and lease duration, are made immediately after the sale of the asset. In a sale-leaseback transaction, the seller of the asset becomes the lessee and the purchaser becomes the lessor.
Similarly, for vector embeddings, this is a process that is outside the core business of any of these AI companies and a distraction.
By offloading this process for each individual company, you solve the problem for each in a silo. After doing this at scale, you become the scaled solution. Another parallel analogy would be Ascend.
Ascend Cell & Gene Therapy Analogy
Ascend is a manufacturer for cell and & gene therapy companies. These types of manufacturers have always provided value by streamlining the manufacturing process, making it cheaper, more efficient, and enabling the biotech companies to focus on what they do best—biotech.
Ascend allows these companies to unload their manufacturing facilities, essentially monetizing their sunken capital expenditures. But they want to do it in a way in which they retain the benefit of having their own platform.
Companies can maintain proprietary access and control of in-house CMC but with the external leverage and cost-effectiveness of outsourcing. As Ascend continues to onboard other manufacturing platforms, it takes what it learns from others and applies it to its overarching product.
Ascend is not just rolling up unscalable solutions, Ascend is the scaled solution, and most of its product development is already done by the companies it serves.
The Scaled Solution
Similarly here, I believe there is a scaled solution. Companies who have individual embeddings of a person can offload it. A multi-layered embedding model of a person can combine the embedding models of multiple companies into different layers.
This becomes the scaled solution in the process. Notably, each company shares their data for the benefit of more data. However, they do not get access to the data and the personal embedding is irreversible. This is still an area of research but I expect this to be accessed through a “universal person key,” similar to Datavant or LiveRamp. This creates a multi-sided data currency that creates a powerful business in the process.

Embedding Networks
What do we think of a future like this? You can imagine having an embedding of yourself and being able to find the person most similar to you in the world.
Groups and Societies are collections of individuals, you can begin to map out and define cultures across the world.
Conclusion
The emergence of AI and deep representation learning sent humanity on a path from which it can never return. Technology is and always will be a double-edged sword. It seems like a logical prediction that the future will be one where our minds are mapped completely.
The future is not set in stone. There are many paths forward where this can end poorly for us. However, I do see a path forward. One defined by trust, where humans own our data and our data does not own us.
If you are interested in this important problem, I’d love to speak with you.
jonathan@irreverent-capital.com
What da math? Have you heard of Anton Petrov. You should subscribe to his YouTube channel. He just released this video recently about mapping of a fruit fly brain. Check it out:
https://youtu.be/0AgAcarLnU4?si=kdVhanR1ulwYP2ll