Project Delta (∆)
A Tool to Decode Yourself

NOTICE: This is an incomplete version that will be refined after further experimentation.
“To know thyself is the beginning of wisdom.” - Socrates
Yeah, yeah, this dead horse has been beaten by every philosopher. I’ve been thinking about technology and how we can use it to solve this problem at last.
While it sometimes feels that the explosion in LLMs is overblown, the underlying math & engineering really is a spectacular discovery that enables us to rethink how we interact with and learn from our text.
In Project Delta (∆), I propose a new method to use our data (specifically long-form writing) to extract our “ideological fingerprint” that maps a writer’s beliefs, values, and interests in feature space, and ultimately benchmarks them against others. If each human had an operating system and code base, what would it look like? Maybe we can use our data to map it out.
The implications of this are significant. The first step to solve any problem is to define it. Most people haven’t even defined themselves, restricting the way in which they wander through life. I imagine a world where people know their convictions, beliefs, values, and how they line up against others, so we can start having real conversations about progress.
Knowing Yourself is Oddly Difficult
Everyone is trying to know themselves. People go to psychiatrists, girls read you by your horoscope, employees seek to understand their strengths and weaknesses. Artists find their voice. It seems true that understanding yourself is a useful endeavor. It’s helpful to understand your limitations in order to avoid them and your strengths to use them. It’s helpful to act objectively and to detect personal biases. It is valuable to understand your beliefs/interests and how they differ to others, to properly frame how you see the world. It’s also valuable to benchmark your beliefs against others to call into question your assumptions. Should you entertain the possibility that the world isn’t flat?
But for some reason, it is incredibly difficult to know yourself. It sometimes feels like the people around me understand my personality better than I do. Perhaps it’s because I live in my own head. I could not possibly understand what is going on in the head of the short and square businessman sitting next to me on the bus, or unwrap their conscious and unconscious beliefs. Even if I could, this would then just present a sample size of n=2, which is entirely unrepresentative of the global population N=7,951,000,000.
Bottom Line: Knowing yourself is an important problem, but it is very difficult to do. Today’s tools to benchmark our personality, ideas, interests and beliefs are nonexistent to poor at best.
Personality Tests
The closest thing I can think of are personality tests such as Enneagram or Big 5, which are broad attempts to categorize individuals in different buckets. Often, these tests are taken with multiple choice. They are more of an If-Then statement than anything else. But of course, humans are much too nuanced to be bucketed in such ways.

This fellow JP feels the same way.

We Can Do Better
This sucks. These categories are only 2-dimensional. In reality, they should be n-dimensional and influence one another better than the current research does. If you wrote a book on your life, what would be in it? What texture would the language take?
I came across this project a Computer + Cognitive Sciences student at Berkeley named Sarvasv Kulpati put together, in which he explores the hypothesis: can we detect writers from just their progression through LLM latent space?
This is an interesting question. Does our writing style distinguish ourselves the same way in which we have “fingerprints?” He experiments with the way a writer “stumbles through feature space” and charts out the below 3 authors’ journeys relative to baseline. He doesn’t quite explore what the variance here implies with each author, but I do believe there is more to be done with this work.
It does appear that each writer has their own “shape.” We will return to this point.
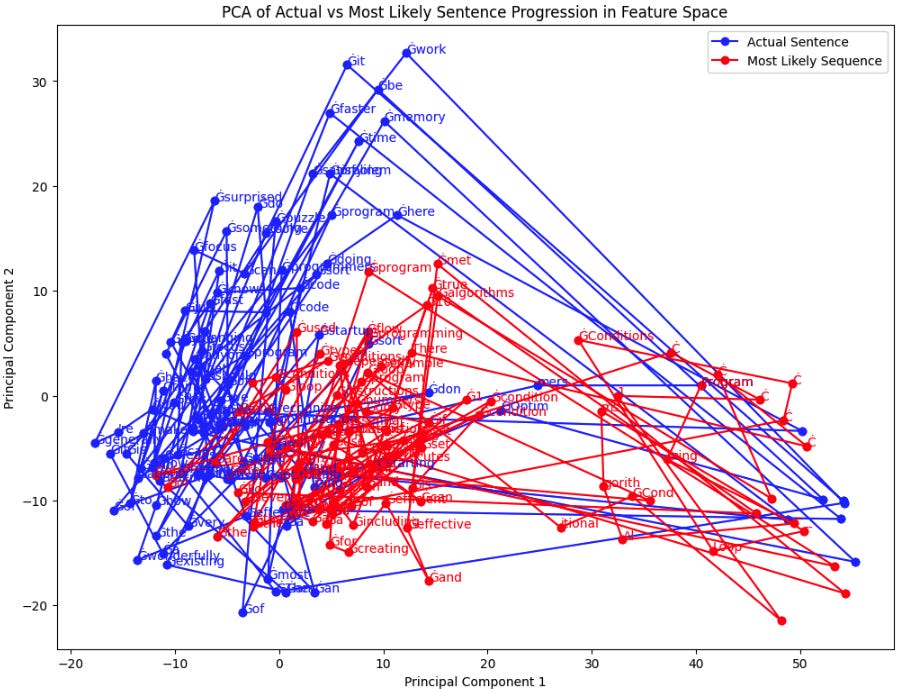
Why This is Really Important
If it is true that each writer’s language takes its own shape, perhaps we can begin to learn more about the writer from their fingerprint. I’m not talking about their grammar. I’m talking about the essence of who they are as a person. I’m constantly drowning in thought trying to understand myself and how I differ from others. Of course, no one can answer this question. Existing solutions, shrinks and tests, suck.
DISRUPTING THE PSYCHIC MARKET!!!!!!
Most of the use of LLMs today really just answers questions as a highly intelligent form of word guessing. There may be a way to use the underlying machinery to actually map out ideas (more on this later).
Some Questions This Tool Could Answer
Answer the question, “who am I?”
What if you could map out an entire person’s personality, beliefs, and interests from the cues left in their writing?
What if you could quantify and plot ideas throughout history (the “Google Trends” of history)? Plot the zeitgeist of history.
What if you could detect points of inflection in your own life in your writing, where certain events or experience triggered new understandings and beliefs that altered the course of your life.
[1] Other potential use applications in the appendix.
This Project
We will take this project through 4 or 5 steps. It doesn’t escape me that this will be an extremely heavy lift for me given my amateur coding skills.
(1) map next word prediction against baseline
(2) vectorize and map text in an n-dimensional space
(3) identify patterns in “idea space” and abstract clouds of vectorized words in close proximity
(4) benchmark results. After the text has been vectorized, vectorize a benchmark of text or word progression. What are the different shapes that the text takes, and how do they differ?
(5) [Maybe] productize this software
(1) map next word prediction against baseline
I’d like to replicate Sarvasv’s work to compare my writing to the “average,” (actual sequence vs most likely). So the following:
Ingest and scrub my data, first focusing on files I have downloaded from substack.
Replicate the experiment for multiple new.
Loop through every word in the sentence, getting the hidden state vector of 0 to n-1 passed into the model
Perform PCA on the features, and then use the axes with the most variance to plot the points
Use Microsoft Phi-2, it seemed like a pretty powerful base model
After the base experiment, try this with multiple essays and compare results.
(2) vectorize and map text in an n-dimensional space
Once we’ve made it this far, I’d like to once again take my text and this time vectorize the whole damn thing.
Example image from this overview from 3Blue1Brown (the best I’ve seen yet).


Question: do I need to tokenize the words for this exercise?
(3) identify patterns in “idea space” and abstract clouds of vectorized words in close proximity
There will be certain clustering of vectors. I’d like to repeat the structure of the experiment in [1] with [2] and map out the vectors in latent space. It may be difficult to visualize. We aren’t dealing in 3 dimensions here. I’ll have to figure out the best way to go about this. Probably by finding the minimum difference between groups of terms. Or the aggregate Delta ∆.
(4) benchmark results. After the text has been vectorized, vectorize a benchmark of text or word progression. What are the different shapes that the text takes, and how do they differ?
After you have mapped your ideas in visual space, can you benchmark them against other people or even the “average” of ideas?
Questions:
Are there any established methods for mapping out abstract thoughts in latent space?
Are there any researchers working on this? Will this be incredibly difficult?
How much text will I need to do this? Will I need to use authored text with significant writings on particular topics as a proof of concept?
Extra Credit:
Can you plot ideas throughout time? Can you capture the zeitgeist of history and see how ideas have changed.
A friend of mine sent across this House of Commons Hansard archive of debates between 1803-2005. What is interesting here is it offers a logged, structured forum for seeing how ideas and beliefs have changed over the years in a tug-of-war.
Literature Review
Appendix
[1] Use Cases
Broad problem: People have difficulty understanding themselves. Generally, how are you as a human unique?
Writing editing (beyond grammar, beyond structure) of the root of the ideas in the text
Therapy or Psychiatry, unpacking your thoughts and laying them out for psychoanalysis either by the computer, you, or the human profession. Writing therapy. Write about your problems. Computer helps you understand and solve them.
General tool to unpack ideas within a piece of writing
My personal use case: I have my own thoughts on a variety of topics in a vacuum (my own head) that I believe to be true.
If there are generally accepted arguments against them, I would like to understand them and decide whether to adopt them.
I think there is a ton of value in realizing an idea or belief you have that others don’t is both unique and correct. These are the ideas that shape the world. This is essentially all scientists, philosophers, etc. have done throughout history.
Research papers all introduce a problem by examining existing ideas, studies, and findings that have been determined, in order to build upon them.
An AI agent that self-plays with ideas can come up with breakthroughs by itself.
This type of agent could in theory produce its own data and continuously improve.
Substack’s vision is to build a new economic engine for culture. I think they would acquire something like this.
Summarize your own mind and digital footprint. Who are you?
Track your data over time. See how your beliefs, health data, etc. have changed. What were major inflection points in your life.
Identify your cultural traits. Which company shares them most? Which city shares them most? Which group of people shares them most? Which religion shares them most? Where do you belong?
Maybe deviation from average isn’t the goal. Can you compare yourself to certain minds throughout history? I.e. you seem to mostly believe this. Abraham Lincoln would have agreed with you on this but disagreed on this (based on his written history).
We may now actually be able to capture the zeitgeist of history? What beliefs have emerged recently? Can we then evaluate the ones that are temporary and the ones that will stay?

[2] Your Personal Data
For years, big tech has had a better understanding of us than we have had of ourselves. You’ve heard the stories of the woman who started getting targeted motherhood ads from Target before she knew she was pregnant. You’ve probably even noticed advertisements come up on your phone for products that you had in the back of your mind. Your data is deep and very telling.
Some sources for personal data that I have been thinking about for the use of this project. I’m going to start out with my substack data because the information is the most substantive and representative of my own walk through interests, beliefs, values, etc. It is the best logged digital footprint of me. Twitter probably has too many liked dog videos, but it is a close second.