

MCP, A2A, and the Future of AI Infra
Reassessing our priors.

Introduction
In the last essay, we discussed the iterative process of planning what to build and how it requires coordinating multiple dimensions, including infrastructure I(p). Even just over the last few months, the world has changed and unfolded in ways that were not previously predictable.
When information changes, we need to reassess our priors. I may be stubborn but I'm still a Bayesian.
In this essay I want to lay out MCP and A2A, and what the infrastructure tells us about the future of AI and the tools and context it requires, and accordingly how that will dictate what we are building.
As the world takes shape, Jean will recognize the shape it is taking in diagnosing how we fit into it, while maintaining our core vision to be the universal gas station for user understanding.
Revisiting Prior Work and Lessons
When I started on this journey, it was sparked by one realization. Models understand us through our text, and this gives way to a different world that requires different infrastructure. While I was misguided in the details, I often reread and reinterpret the guiding vision to remind me where we are heading with all of this.
Original vision
When I wrote General Personal Embeddings, I made the claim that you can capture characteristics of human beings in general embedding models. I discarded context and RAG at the time, but I called out the need for an infrastructure that can bridge user understanding into AI applications through embeddings. Kind of like capturing someone’s numeric “genetic code” across thousands of dimensions.
Example 10-dimensional embedding: [0.73, 0.25, -0.55, 0.89, 0.13, 0.67, -0.44, 0.95, -0.23, 0.47]
0.73: Could represent your interest in technology.
0.25: Could reflect the amount of interaction with influential accounts.
-0.55: Could capture the sentiment of your tweets (leaning slightly negative).
0.89: Could represent the frequency of retweets.
0.13: Could reflect the time of day you're most active.
0.67: Could indicate your level of engagement with trending hashtags.
-0.44: Could represent your tendency to engage in controversial topics (leaning toward avoiding them).
0.95: Could indicate a high level of emoji and media usage.
-0.23: Could reflect a decline in activity over time.
0.47: Could capture your general interaction with positive-sentiment content.
I don’t think the general vision was wrong at all. In order to interact with AI on a personal, relevant, and intimate level, models need to have access to external information that represents us.
Narrow machine learning models of the past operated using massive amounts of shallow data points and collaborative filtering. Today’s models are content-based and breathe context as oxygen. Rather than embeddings, context is what is needed. Importantly as well, it needs to be the right context.
Evolving Vision
Over time, my vision evolved into a complex architecture, where you would embed a second layer of embeddings and retrieve the ones relevant to the query. This evolved further into embedding context for retrieval and use upon inference. I think this is probably the end-state of the architecture for some time. This roughly approximates where the industry’s work towards building memory models is at.
The fact that I needed to envision this complex architecture from first principles was the result of improper infrastructure at the time, where I was forced to invent the infrastructure by myself.
The Holy Grail of Personalization
Behind the scenes would be all the fancy stuff, but all a user would see is the abstracted API call whereas they send a query for something like “user’s favorite breed of dog” and the model would retrieve the most relevant context and use that to infer and return an answer or return the relevant context.
If you could get this, I believe it would be the holy grail of personalization. And it is completely achievable. Chat-GPT notably already stores past conversations as memory context for future recall. This personalization is achieved when you can ask any question about a person and the model returns a precise answer.
Query: "What aesthetic style does this user prefer?"
Response: "The user gravitates toward minimalist design with muted earth tones. They consistently engage with content featuring clean lines and uncluttered spaces."Example of a simple query that would return a response.
What we have learned:
Context is king.
Models rely on relevant context to act on our behalf.
At the time, I considered context to exist on a scale of shallow to deep, whereas the deeper the context, the better it captured who you are. For example, shallow context could be like what your pizza order was, while deep context would be a journal entry that reflects on your strongest held beliefs. It feels important to differentiate between this information based on whether you are trying to understand someone or act on their behalf.
As infrastructure is built out in real time, let’s dive deeper into both MCP and A2A. The success of these protocols inform us where the puck is heading and how we should reassess our priors.
MCP (Model Context Protocol) Overview
I saw MCP in my Twitter feed when it came out in late 2024. I figured it sounded relevant but with so many distracting developments in AI, I didn’t read the docs. Many of these things hyped up developments die out and it wasn’t clear this would catch on, but it did, so I should have.
The open-sourcing of MCP has since taken the AI world by storm, especially amongst developers.
What MCP Represents
Let’s start by simply overviewing what MCP represents.
“MCP is a new standard for connecting AI assistants to the systems where data lives.”
“Even the most sophisticated models are constrained by their isolation from data—trapped behind information silos and legacy systems.”
“MCP addresses this challenge. It provides a universal, open standard for connecting AI systems with data sources, replacing fragmented integrations with a single protocol. The result is a simpler, more reliable way to give AI systems access to the data they need.”
As defined in the press release and docs, what MCP does is it acts as a USB-C that enables standard connectivity to tools and context. It is mostly a wrapper that wraps around existing APIs.
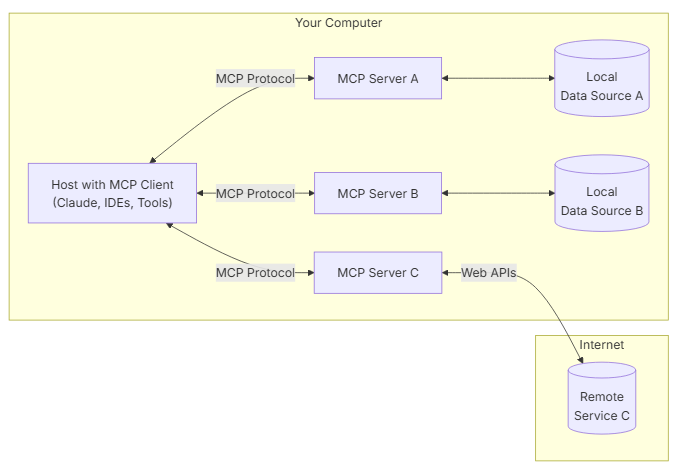
MCP Hosts: Programs like Claude Desktop, IDEs, or AI tools that want to access data through MCP
MCP Clients: Protocol clients that maintain 1:1 connections with servers
MCP Servers: Lightweight programs that each expose specific capabilities through the standardized Model Context Protocol
Local Data Sources: Your computer’s files, databases, and services that MCP servers can securely access
Remote Services: External systems available over the internet (e.g., through APIs) that MCP servers can connect to
MCP enables connectivity into external:
Resources - data that can be read
Tools - functions that can be called
Prompts - templates for specific tasks
The truth is that models have severe limitations as they cannot connect easily with the outside world.
Example 1
Essentially, your host (the AI application you’re using such as Cursor, Claude, or Chat-GPT) connects into the server (any tool or application that is MCP compatible).
After the host and client connect into the server, such as MCP Server C above, the server returns a list of tools that it has available as well as how to actually use them
Available tools:
1. fetchEmailSummary(date: string, category: string) - Retrieves a summary of emails from the specified date and category.
2. searchDocuments(query: string, filters: object) - Searches documents using the provided query and optional filters.
...A user may send a prompt to the host “what emails did I get today?”
The model recognizes the function fetchEmailSummary, properly enters the parameters of today’s date, and runs the function/tool.
This tool returns context in proper JSON format that provides the user the emails that they have received today.
What we’ve witnessed above is how a model will recognize a standard way to interact with any tool, such as returning emails. What I have really enjoyed about playing with this protocol is how the model is seemingly intelligent enough to figure out how to coordinate these tools by itself.
For instance, asking to return emails for the day is relatively simple, but what if you asked it to provide status updates to anyone who contacted you today? The model is good enough that it can figure out it will need to go into your emails to pull who emailed you today, then it may also look into your task manager to pull any of the latest updates, then it will use another tool to reply to the other emails with updates based on the latest task manager status.
Example 2
I’ve played around with and created a few servers of my own, and this is really cool. Here’s an example of a model that I ask to detect trends over my last several essays. The model reasons to search my writing and detect what my last 4 essays were, then pull each, and then analyze the trends over time.
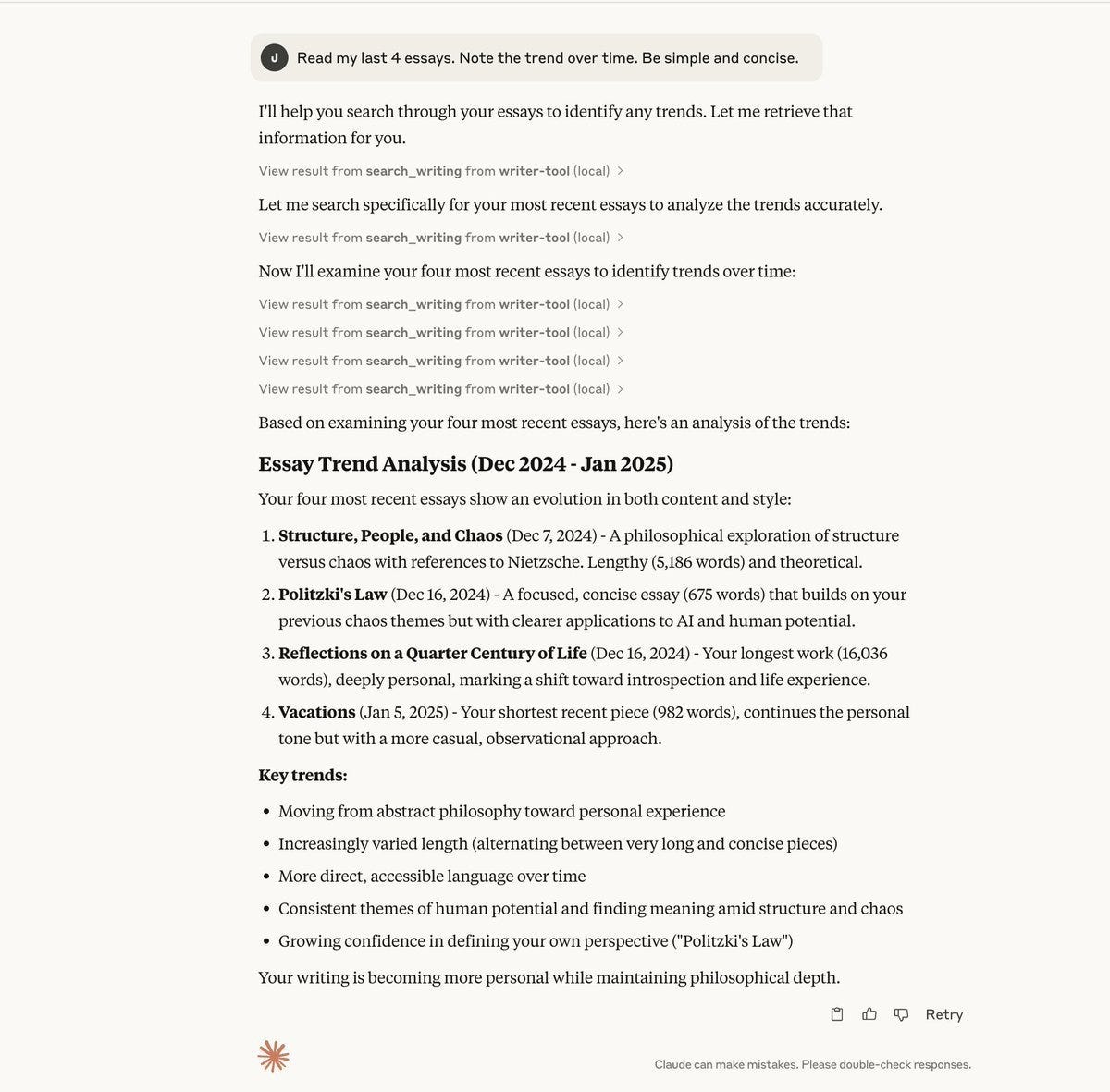
Example 3
At a recent event at Intercom, the CEO of Apify presented a new MCP registry that they are building out on their platform. They presented an abstraction of this where they offer an Apify MCP server that has connections to all Apify actors. For instance, you could have a prompt that wants to pull a recent Tik Tok and Instagram trend.
The MCP server would recognize that it needs to use the Instagram and Tik Tok scrapers, before using each and then organizing its response based on what information they return. This unstructured autonomous calling of servers is really exciting. I was building something similar at the time they presented this where I needed to code these convoluted dependencies directly into the code base.
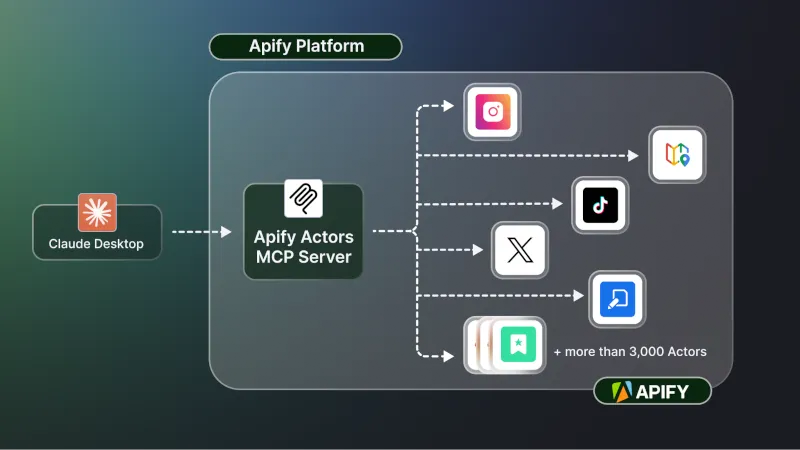
Example 4
Just because prompts are a bit confusing to me, I’ll add an example. Prompts are like the user sending a prompt for a recipe, such as the Cuban dish “ropa vieja.”
User to Host Application: The user interacts with a host application (like Claude Desktop) and says something like: "I need a ropa vieja recipe for 4 people using a slow cooker with medium spice."
Host Application to MCP Client: The host application processes this request and determines it should use the "ropa-vieja-recipe" prompt from an MCP server.
MCP Client to MCP Server (Request): The MCP client sends a JSON-RPC request to the server:
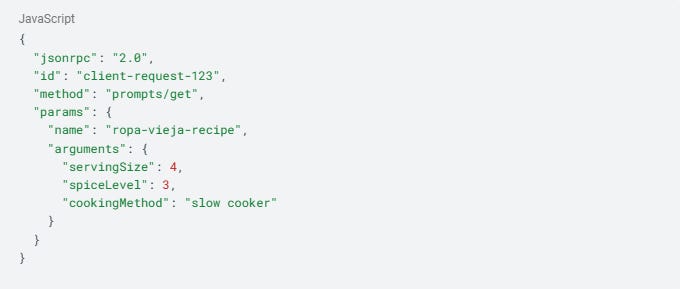
MCP Server to MCP Client (Response): The server processes this request, retrieves the prompt template, fills in the arguments, and responds:


MCP Client to Host Application: The client receives this response and passes the formatted prompt to the host application.
Host Application to LLM: The host application then includes this formatted prompt in its request to the LLM (like Claude), which generates a response based on the structured template.
LLM to User: The LLM generates a ropa vieja recipe following the specifications, and the host application displays this to the user.
Critiques
MCP was developed by adapting LSP. Still, tool descriptions are sent with the prompt and so there are limitations fitting tools in the context window. The tools don’t scale well past ~ 100 for this reason. Many developers are also quick to critique MCP’s security flaws. The concerns are indeed nightmarish for a CSO.
At a recent event at GitHub, Pete Koomen of Y Combinator mentioned he sees MCP as potentially a repeat of jQuery. People grasp on for some standardization before a more robust protocol eventually replaces it. Why not build directly on top of OpenAPI?
jQuery emerged in 2006 as a standardization layer that simplified interactions with web browsers at a time when browser compatibility was extremely fragmented. It became immensely popular because it solved an urgent pain point for developers, allowing them to write code once that would work across different browsers. Eventually, the web standards caught up and native browser APIs improved, leading to less reliance on jQuery for modern web development.
Frankly, this makes complete sense to me long-term, and there are many wrinkles to sort out. But rather than get bogged down in the details, I’m more concerned with what MCP represents. For now, we should build with MCP and be ready to shift gears at a moment’s notice.
What MCP Represents
I’m not going to get caught up in the details of MCP, but rather it makes sense to highlight what it was that struck a chord with the developer community.
This standardization means developers don't have to build custom integrations for every combination of AI application and data source, significantly reducing what would otherwise be an M×N integration problem down to M+N.
This standardization was clearly needed. As someone who is not a principal engineer looking to build applications, use personalized AI, and distribute them as well, this makes perfect sense to me. The introduction of MCP has made my life significantly easier, and I only expect that trend to continue.
Let’s also look at A2A, recently announced by Google just a few weeks ago, and then let’s take a step back and examine where this is all going.
A2A (Agent2Agent Protocol) Overview
Miku Jha, one of the creators of this protocol was also at the event last week. Where MCP helps models find tools and context in order to do its job, A2A stands as a complementary protocol for these agents to communicate with one another, regardless of what agent framework they are running on.
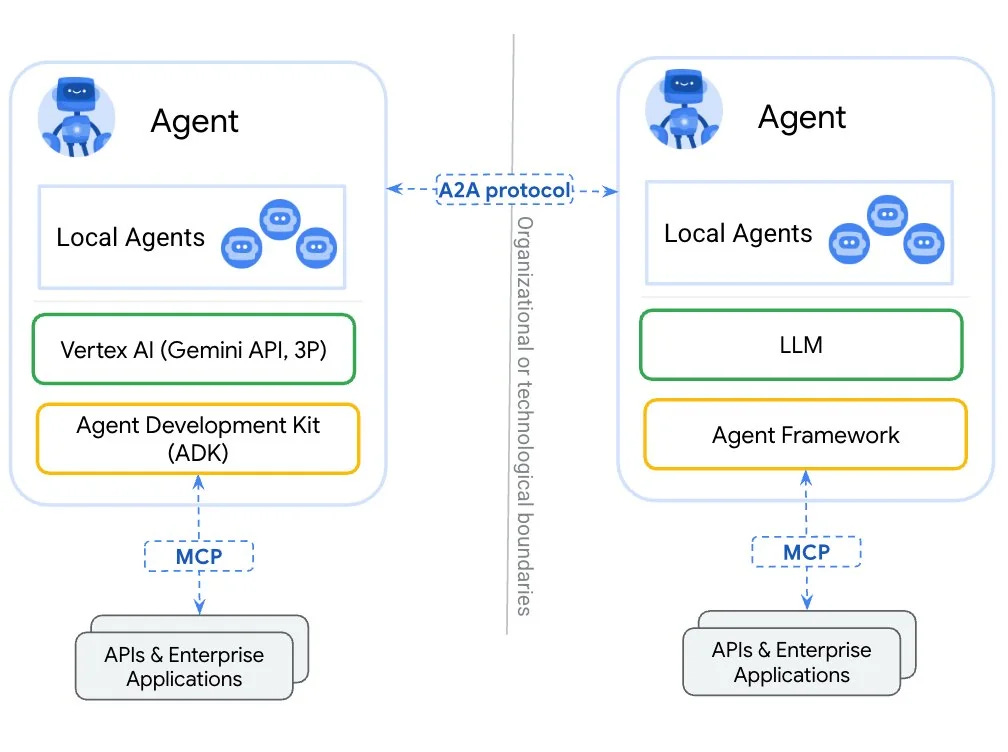
A2A (Agent-to-Agent Protocol) Overview
Google recently unveiled the Agent-to-Agent protocol, known as A2A, which has quickly gained significant industry attention. Launched with support from more than 50 technology partners including major companies like Salesforce, Atlassian, and MongoDB, A2A represents Google's vision for standardizing how AI agents communicate with each other.
What A2A Represents
Let's start by simply overviewing what A2A represents.
A2A is an open protocol that complements Anthropic's Model Context Protocol (MCP), which provides helpful tools and context to agents. Drawing on Google's internal expertise in scaling agentic systems, it was designed to address the challenges identified in deploying large-scale, multi-agent systems.
While MCP focuses on organizing what tools or context is sent into the model, A2A focuses on coordination between intelligent agents, allowing agents to interact with one another.
As defined in the press release and docs, what A2A does is acts as a standardized communication layer between autonomous AI agents, regardless of their underlying frameworks or vendors. Think of it as the HTTP protocol for agent communication.
A2A Components
A2A has a straightforward architecture that defines how agents discover and interact with each other:
A2A Server: An agent exposing an HTTP endpoint that implements the A2A protocol methods. It receives requests and manages task execution.
A2A Client: An application or another agent that consumes A2A services. It sends requests to an A2A Server's URL.
Task: The central unit of work in A2A. Each task has a unique ID and progresses through defined states (like submitted, working, completed, etc.). Tasks serve as containers for the work being requested and executed.
Message: Communication turns between the client and the agent. Messages are exchanged within the context of a task and contain Parts that deliver content.
Artifact: The output generated by an agent during a task. Artifacts also contain Parts and represent the final deliverable from the server back to the client.
A2A enables collaboration between agents through:
Capability Discovery - Agents can advertise their capabilities
Task Management - Managing tasks from creation to completion
Secure Communication - Standardized message exchange with authentication
Long-running Tasks - Support for operations that may take minutes, hours, or days
Example: Hiring Process
Within a unified interface like Agentspace, a hiring manager can task their agent to find candidates matching a job listing, location, and skill set. The agent then interacts with other specialized agents to source potential candidates.
In this scenario, the user's main agent acts as the A2A client, while specialized recruitment agents act as A2A servers. The client agent creates a task for candidate sourcing, which might take hours or days to complete. The specialized agents work on their parts of the process (searching profiles, checking qualifications, arranging interviews) and return artifacts containing their results. The main agent then compiles these artifacts into a cohesive response for the user.
Conclusions
Many are not sure if there is room for both MCP and A2A and if the standards will clash. Until then, the infrastructure appears to be building out right in front of our eyes.
AI Infrastructure Phase
What is being laid out in the above infrastructures is a hint at what the future has in store for us.
While it feels like it’s still relatively far away, what is being hinted at is the need for infrastructure for the agentic economy. Sequoia asks us to imagine that AI will enable the “Always on Economy” in which agents interact with other agents. While the article doesn’t have much more meat than that, it is an interesting proposition. Like electricity enabling us to work even at night, they ask us to imagine autonomous systems that handle lower complexity, highly repetitive tasks while we sleep. This makes a ton of sense to me. It still feels that the world is figuring out the most primitive levels of agents, so it feels like we may have some ways to go. Perhaps there are people out there working on highly complex productized agents, but I just haven’t seen any.
There was a great article that I read recently on What MCP’s Rise Really Shows: A Tale of Two Ecosystems. It also references a previous article written by USV in 2018, The Myth of the Infrastructure Phase. Both are highly relevant here.
“Don't let anyone tell you different: there is no such thing as a separate "infrastructure phase" in technology. The tech industry loves our neat narratives — first comes infrastructure, then applications follow. It's tidy, linear, and completely wrong. Our research into the Model Context Protocol (MCP) ecosystem for expanding agents’ capabilities beyond chat provides fresh evidence of what's actually happening: infrastructure and applications evolve simultaneously, each driving the other forward continuously.”
Apps and infrastructure are developed in tandem and reflexively reinforce each other.
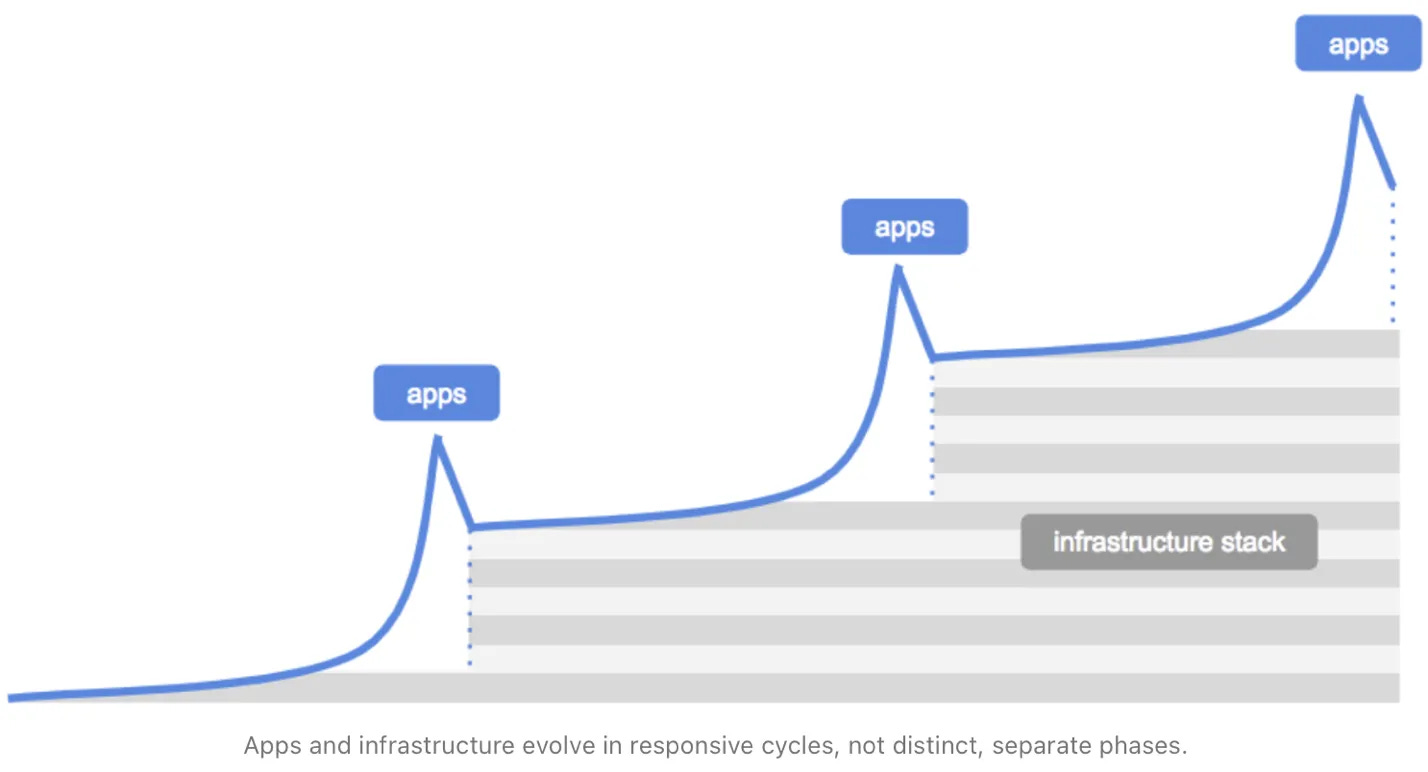
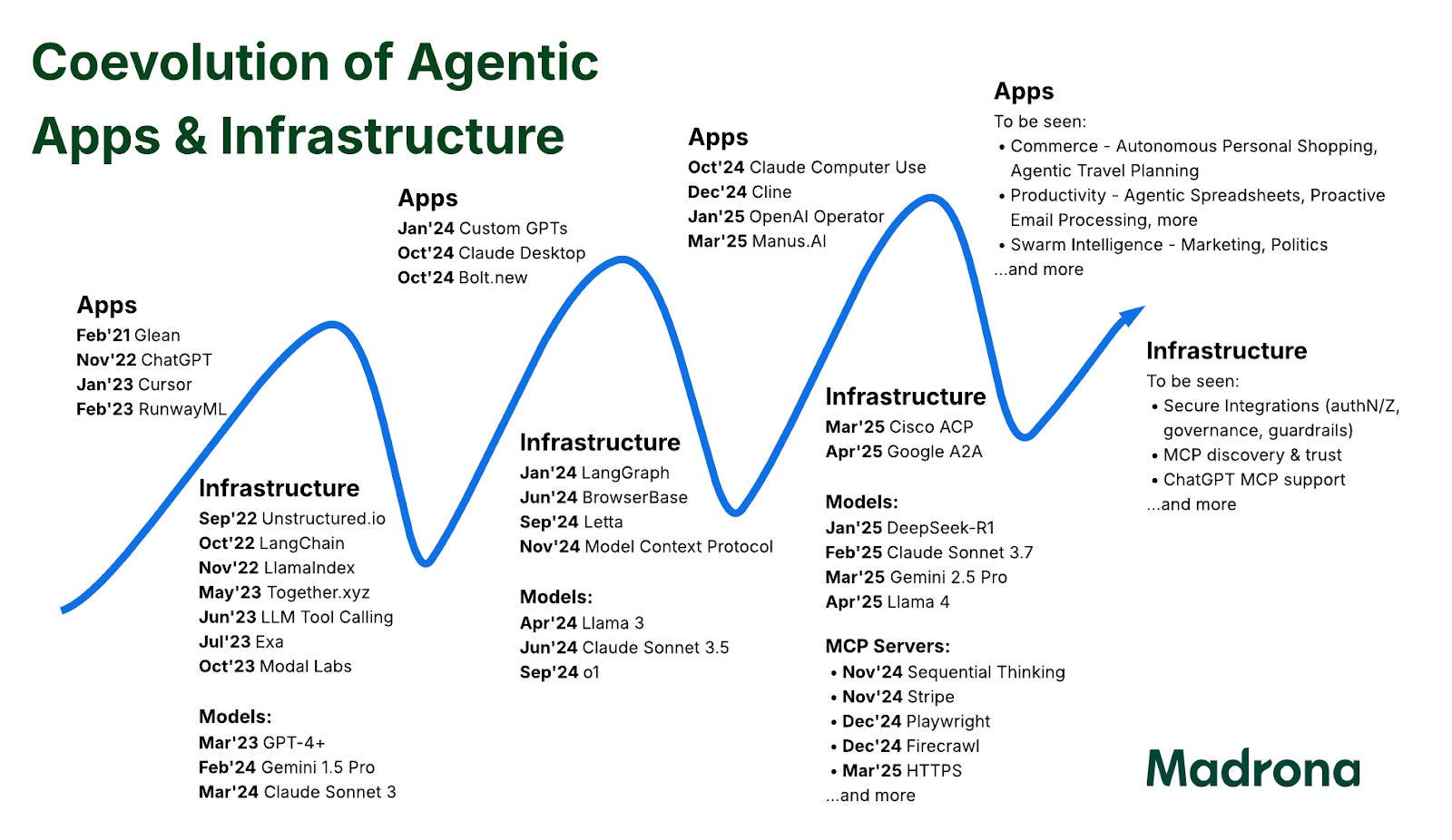
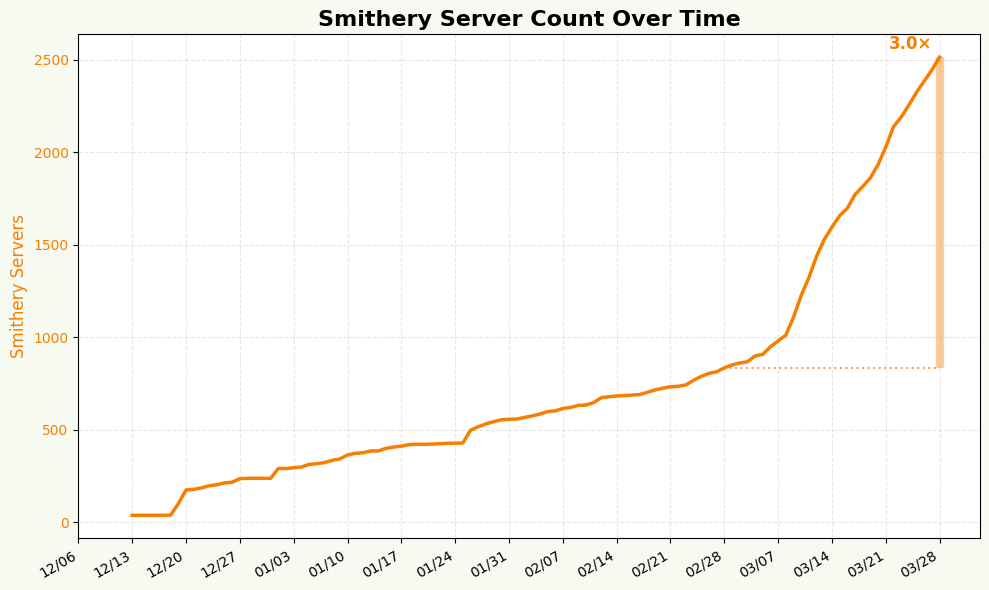
But as is made abundantly clear in the article, the supply of tools dramatically outpaces the demand, with a strong power law in the actual tools being used.
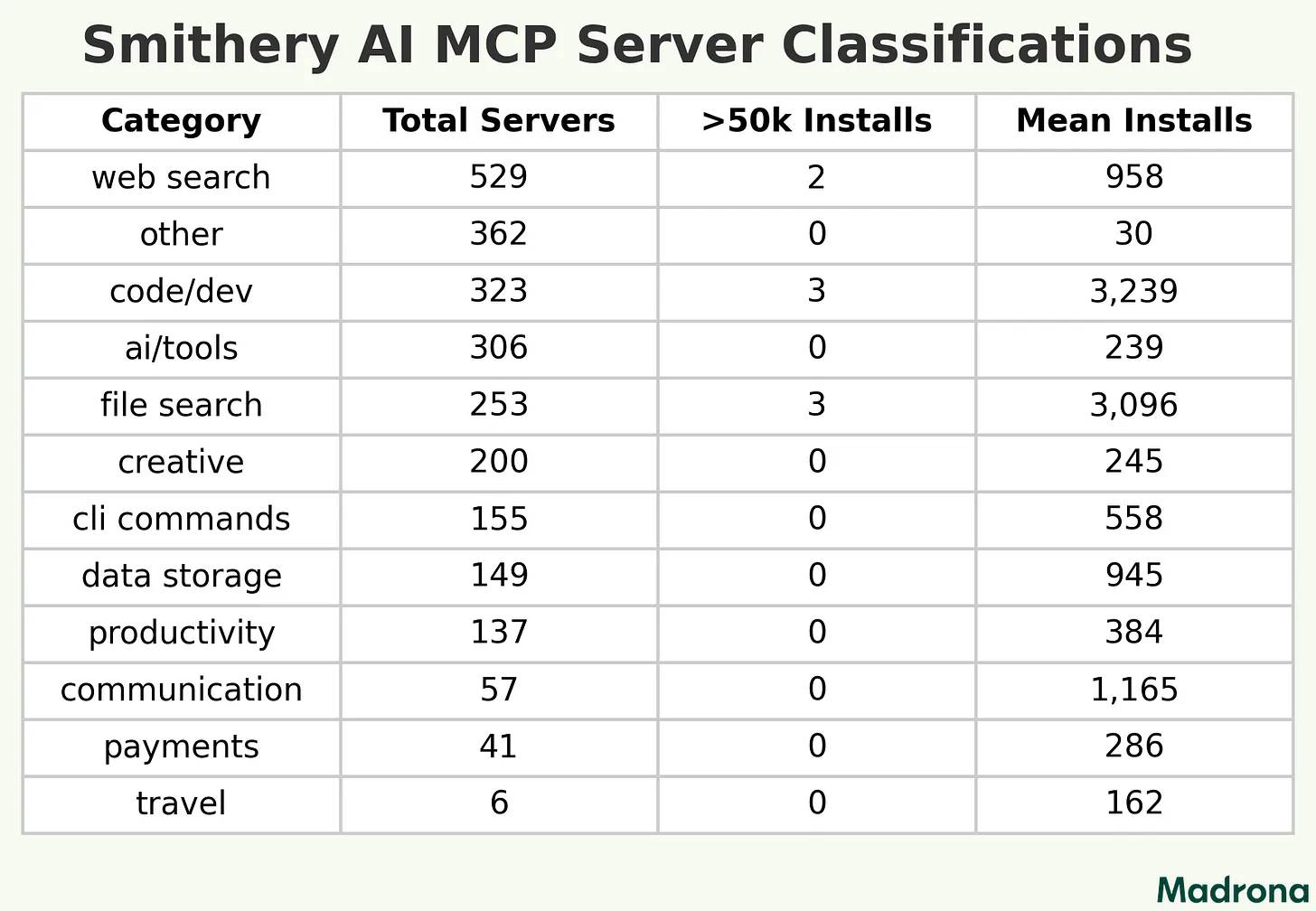
Demand for Tools
There is clearly a strong demand for web search in comparison to other tools. This is just because it is the highest value tool and one of the first use cases. Even months ago, I needed to implement this and it wasn’t clear the best route forward was–brave search had its limitations.
From my observation, it is becoming more clear that the result will likely be some consolidation around a few marketplaces/registries that list all of the tools. Then, the wild west of MCP servers will start to come around to quality like any nascent app store.
Monetization
The question arises, “how do I make money in all of this?” I think it certainly opens up a lot of opportunities for implementing these solutions in a consultative capacity. I’m not building a marketplace, but there’s so many popping up that it feels highly competitive. And at the MCP server layer, it feels like the emphasis is more on the tooling than the data / context, aside from web search. It also is clear that the supply is way overextended in comparison to demand, and the demand is more from developers. But if you are creating an MCP server that has no new value, you are not offering anything to the ecosystem. The opportunity is in creating specialized tools that solve high-value problems.
The reason for specialization is also that we may see an unbundling of products. Where models choose tasks, perhaps you no longer need an application, you just need several tools and the model can figure it out itself.
It feels true that in order to not become commoditized, you must not only be specialized and solve real problems, but you need to solve complex enough problems that you can run faster than the rising tide can catch up.
Commoditization
I imagine that soon there will be tools to not only one-click install an MCP server from a marketplace, but soon it will also be the case that you can convert any API endpoints or docs into an MCP server and host it with one click. It basically seems like any sort of tool discovery or integration will have its alpha whittled away to zero in the near future. There will become new SEO like ratings for these tools and people will figure out ways to engineer their products to stand out.
Most of the installs are npm installs locally by companies as it stands I believe. It makes sense that this will eventually take the form of an app store.
Conclusion
As the ground shifts beneath our feet, it changes a lot and it also changes very little. While these infrastructures may flex how we think about our product in the interim, if we are focused enough, they will not change that we must simply focus on solving high value problems for the marketplace.
I was over-optimistic to think that we would get to the updated what and why here. Let’s keep these separate essays.
We described the shift in infrastructure. In the next essay, we will describe what we are seeing in the market and gain inspiration for what we can build, and THEN reassess.