Engineering Context
Coordinating Retrieval and Inference

Theory and Practice
To think about solving new problems, I try to balance the theoretical and the practical. These are difficult dimensions in isolation, but I believe that the best products and businesses coordinate them. I’ve been thinking about context theory, memory theory, and what our users want.
Memory
I only recently grew into the “AI Memory” space after observing it from afar. Specifically, I saw the open-sourced memory architectures that were springing up (Mem0, Cognee, etc.) and the virality of Supermemory, which seemed to initially offer a way to save down and recall things like bookmarks or personal context. At roughly that point in time, I had created my own “memory” architecture that closely mirrored these solutions where you embed different memories for later retrieval. While memory is seemingly the closest thing that resembles my interests, the problem is that it is a broad umbrella term that can mean many things. We will disentangle this concept.
At the time, it was NOT impressive to me that these solutions were tailored to chat bots and low-latency, shallow retrieval of arbitrary context like something you bookmarked on twitter.
From the theoretical angle, I was very focused on “relevant context.” Context that is helpful for understanding the individual at time of inference.
Context Engineering
Recently, I came across a tweet from the CEO of Shopify and Andrej Karpathy on how we should think about this terminology in the Age of AI. What does it mean to engineer a prompt? You want relevant context, but you also don’t want to flood the context window.
Andrej calls out the need to:
- break up problems just right into control flows
- pack the context windows just right
- dispatch calls to LLMs of the right kind and capability

And this has had me thinking a lot about my own solutions.
Something I posted this morning:
I’m not sure I even like the term “memory” for your context. It makes it feel like retrieving “forgotten context” is its main purpose.
The main purpose of this context retrieval and “context engineering” is that upon inference the AI is provided select, relevant context for whatever its task may be at that time.
Context windows will expand, and indeed memory retrieval systems will improve, but this will never be about being able to “recall past information” or “infinite chat windows.”
You can think of recommendation engines and machine learning and now AI models as engines. We used to need oil (traditional data) to train these models. Now we need tokens/embeddings (gasoline) upon inference.
These models are trained on the *average* person. By default, the next token predicted is always going to be generic.
It is only by engineering context that these models will be brought to their full potential. Where the right context triggers vector programs within the LLM’s “vector database” not often used, but the correct program in that case.
In such high-dimensional space, this sounds simple but it is far from it. It’s like playing battleship across the entire universe and never hearing a response. [LINK]
The point that I really wanted to get across here is that what really matters is that data has fundamentally changed. It’s not about having a ton of data to run in your models anymore. What matters now is that you pull a select amount of highly useful context that is helpful upon time of inference.
It doesn’t feel right to say that either retrieval or context is the most important. They are both important so you can have the right prompt at inference. And this is a dynamic requirement. I’m thinking about what this may mean for Jean.
In order for us to understand how to truly engineer context for our users, let’s first take a look at how it is currently designed and then how our users have been using the product.
EDIT: As I sit here re-reading this, I just saw another post in my feed from the founder of Mem0 saying something similar.

Add/Search
Jean’s MCP currently has 5 tools:
Add Memory (add_memory)
List Memories (list_memories)
Search Memory (search_memory)
Ask Memory (ask_memory)
Deep Memory (deep_memory)
But even these tools roughly fall under two capabilities.
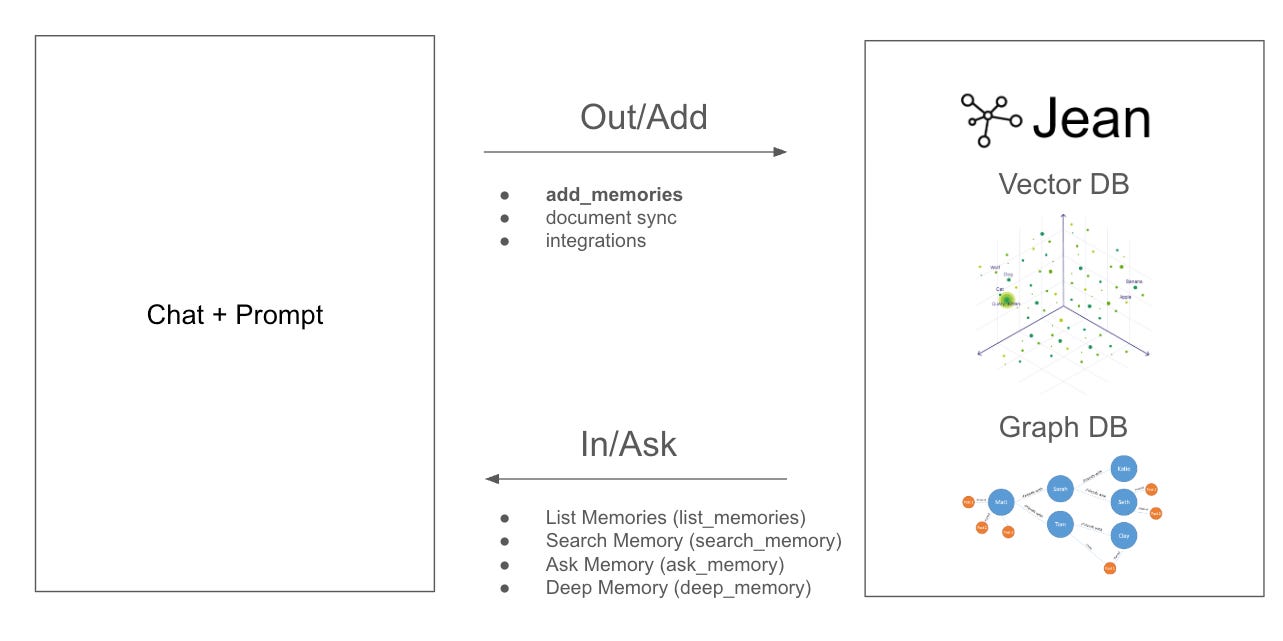
You are either saving down new context or you are retrieving context. These are two distinct operations and the flow is either in or out of the chat.
Each of these are much more complex under the hood, the goal is to present them in as simple of a way as possible to the user, but for them to be capable of always learning and updating the knowledge base and to always have the most relevant context (context engineering) at time of inference.
Right now, saving down new context is set to “always on” but retrieving context must be prompted. The reason is not all prompts would benefit from memory. See below.
Not All Prompts Are Created Equal
How exactly this context engineering triggers depends on how the user wants it to work, which we are still learning. In the last essay, I lay out some of these learnings, but I don’t quite close the loop on how to engineer this for them. Different people use it in different ways, so the goal is to build it so that it works great for some people. The north star is always to build it so that it works great for ANY inference. This is harder to achieve but I think it should be something to strive for.
Some examples of different prompts:
What’s the capital of Thailand? → No personal context needed
What did USER X say in our company slack? → Needs specific communication history and relationship context
What positions might I be a good fit for at NVIDIA? → Needs deep personal context about skills, experience, values
Each of these prompts differ in their need for context at time of inference and the type of context. It is also not trivial to pull context, it has to be the right context. So there is a certain amount of thinking and orchestration that is required in all of this. Our current tools are very primitive in comparison to what could be.
Also, the context may be identified as relevant through either RAG or inference itself. My belief is that to the extent you can do it through attention/context, you should (Software for the Individual), but there are practical constraints on compute and latency that always need to be considered. Please Gemini Flash, keep improving 🙏. There is a new version of Flash that I am looking forward to testing here.
It is also relevant to control for the time that recent memories were stored. Is this a fresh chat? People seem to want to have a form of a “working memory,” per our last post.
.
.
.
.
.
Okay so now let’s think about user wants and how to bridge this gap.
.
.
.
.
.
.
User Feedback
Ideally, we take some of our theoretical and practical understanding of how this should be built and coordinate it towards how our users are actually using it. We also have constraints on how MCP works within different platforms like Claude and Cursor. This isn’t an easy part of this coordination.
Understandably, users just want this to work. One of the biggest points of friction seems to be that users just want to be able to say something and then for the model to remember it for future responses. Something like always speak to me in my favorite language. I doubt the average user goes in and edits their system prompt, but what they seem to want is a dynamic system prompt that recalls certain preferences at the correct time. This is where I think we could ultimately provide the most value.

The problem is that Claude is simply not built in this way. You can go into Claude’s system prompt and edit it, but most don’t. Claude works in a way in which Claude thinks, and then chooses tools to use that can accomplish its goal, such as web search. But I do think we can build this in a way that Claude determines what types of information would be valuable to act on behalf of a user (i.e. get working memory, current projects, preferences). And that context is pulled for time at inference.
But we can create a “hack” that effectively makes Claude act in this way. And we are going to create a new version of Jean Memory with this capability.
Effectively what this will look like is an orchestration layer that just does everything under the hood and is always active. Ideally, we will need to build this in a way that it doesn’t add so much latency that it makes it impractical to use. It should actually work as proposed!
The Ideal Solution
Probably, the ideal solution wraps all of our tools into one tool that is always callable and can be forgotten. Any time a user prompts Claude or any compatible client, it sends what has been requested into our tool, where we ultimately decide how to process that request or information.
We will decide then whether there is new information to save down about a person and then save it down, if it is useful context. We will also decide in parallel if there is information or preferences that would be helpful at time of inference and then feed that into the user’s prompt. Further, we will decide at what level of processing is needed. Is this just a simple preference pull? Or will we need to run deep_memory over all of their memories for a deeper examination of their past conversations and preferences.
To the extent we can update our tooling so that it maintains a permanent, but dynamic system prompt, that would also be ideal so that users can say “remember to always” and it always does.
On top of all of this, users should never need to think about it. It should be tied to their hip, and always “just work.”
The Orchestration
Probably, this will require an initial orchestration through Gemini Flash that takes all this information, processes and routes it correctly, and then processes the context that was pulled to pack it nicely for the system to understand before responding.

The Implementation
Okay, well I’m going to try to wrestle something in production today. We will see some of the limitations and bugs by just getting it out there.
—
Thank you. If you’d like to learn more about Jean, check us out at www.jeanmemory.com. Or contact me at jonathan@jeantechnologies.com.
Jean is building the infrastructure for computers to understand us deeply.
Our mission is to ensure AI applications understand users consistently by providing persistent, cross-platform memory that surfaces relevant personal context when needed.
Every time I see anyone talk about prompt engineering or context engineering, I just think back to how combinations of representations underpin nearly all of creativity (see http://cogsci.uwaterloo.ca/Articles/Thagard.2011.creative-combination.final%20copy.pdf).