

Building Jean Memory
Converting Traction to Product

About a month ago on April 29th, I decided to test a new product angle for Jean in the market. On May 28th, we soft-launched it on Reddit. Today is June 22nd, 25 days later.
The test was by many measures a success. 300 people have signed up. We have paying users, 85+ people have starred the GitHub repository, also making us the most popular fork of Mem0 (by far), and most importantly we have learned a lot from our users.
Whereas my writing has historically been quite explorative, this seems to have taken a different form, reflecting my predicament. I now have more feedback than I know what to do with and expect that to become more of the case over time. I will flesh out these learnings more over time.
For any readers who may be interested, check it out at jeanmemory.com

As a quick reminder and solidification of Jean’s Vision and Mission.
Jean is building the infrastructure for computers to understand us deeply.
Our mission is to ensure AI applications understand users consistently by providing persistent, cross-platform memory that surfaces relevant personal context when needed.
Our core conviction is that deep learning enables machines to understand humans deeply. In the future, all AI applications will need to understand us in order to act on our behalf. These models already have the implicit training needed to understand us, but they need context of our lives to do so.
The Test
I had a few prior assumptions and hypotheses I wanted to test in the market.
I hypothesized that developers would be the most interested, since they are technical enough to understand and be interested in MCP tooling.
I hypothesized that the data gravity was starting to fall closer to the consumer with recent infrastructure developments.
I hypothesized that these will one day be one-click installs like an app store and that will introduce a flood of more usage. The technical setup is a point of friction.
I hypothesized that the focus should still be on “understanding.” “My instincts tell me that the focus should still be on understanding, but maybe I am just delusional. Perhaps even proper context and memory, when correctly called in a prompt, simply converges on understanding.”
When I first started all of this, I thought that there would be a difference between personal context, such as your values and beliefs, and shallow context, such as what you ate for breakfast this morning and what framework one of your projects is built on.
I hypothesized that there is a certain need for a trusted 3rd party to be the liaison for this context.
I really didn’t think people would be willing to pay for this and that the only way to monetize it would be to one day enable this connection with businesses where users would choose to port their context if they wanted.
There has always been a certain question mark on how you bootstrap user context for something like this as well.
The Learnings
The point of this market test was very simple and was to see if people would be interested in memory across their applications. We had many people jump onto the platform after, showing clear interest from a conceptual level.
The learnings from this cycle have been different from prior cycles. Most cycles before have been isolated hypotheses that I’ve tested with no real feedback. Basically continuously building new tech and becoming a better developer, but getting radio silence from the market.
This cycle has introduced many problems, but they are good problems to have. We now hear a great deal of activity from users, and indeed the problem has been being able to field all of the feedback and keep my head above water while balancing more plates than I have needed to so far. We have a feature road map and list of bugs to fix that extends into infinity.
Something struck a chord. There were many bugs as we sought to launch early and people fell off. Servers failed. As we improved the product, people began using it for hours at a time.
Our first product itself had a terrible UI and it wasn’t entirely clear where to start or how to use it. We want the setup to be as simple as possible. There is still work to be done here.
People are extremely sensitive to any sort of behavior that can be seen as marketing or scammy. The best way to win people over is to just be as helpful as possible. The platform gets received much better with a video of me on how to use it and how to add memory to your applications.
You don’t become trusted by saying “I'm trusted,” you become trusted by acting in ways that are trustworthy. Open-sourced helps with this.
85+ stars on GitHub. Developers trust open-sourced. Contributors welcome.
My favorite tool is deep memory. But people don’t really use it. Perhaps this is just a customer education thing. We don’t have any clear listings of the tools and what they do.
Our setup works in a way that it constantly adds memories during conversation. And this “infinite memory" is usable across all AI applications like Claude, Cursor, Windsurf.
We also have a life graph. At the moment, it’s not all that it could be, but it seems that it is relatively popular.
We are designing this to be a utility and common tool rather than a web app but people still seem to come back to the dashboard.
Many people arrive using their phone on the site on mobile. Roughly half. That is problematic, since we are not designed to be a mobile app. You also cannot download this on Claude as a mobile app.
People seem to be using this as a form of a working memory.
There are different people that seem to use it for very different reasons when talking to users. It feels that you need to make decisions on which user persona you want to optimize the platform for. And there are very real tradeoffs in all of those decisions.
Regarding our questions on how you bootstrap user context, it seems that has largely been solved. The users do it themselves through natural conversation with the AI. We will still need to add high leverage integrations such as Notion to optimize this. We want to be the universal context layer and that means we’ll need to be universal and be able to connect to your context everywhere.
We currently have this set up in a way that it runs add_memory nearly every time you say anything. The other way we could do this is where you need to prompt it. It seems like people don’t actually mind this always-remembering nature of the application. But we will need to talk to users more.
No one has once said “OpenAI has memory though!” I think it will be the case that memory will disentangle from ChatGPT.
“Helpful context”
Probably the most important learning from all of this is that people do seem to want to have access to this context, but it’s not context so that the models can understand them for use in some sort of one-off psychoanalysis situation (though once a context store is up and running that is also being used). People want their models to have a working memory and relevant context for the projects they are working on.
“Perhaps even proper context and memory, when correctly called in a prompt, simply converges on understanding.”
This part was correct. We just need to make sure that it always pulls the right context.
People who use it seem to use it a lot and the memory is tied to their hip. What I didn’t expect was that this would be used as somewhat of a productivity tool. I’ve seen a lot of people say that there’s often no need to reinvent markets. They express that you should go to the tried and true markets, where there is always demand. They seem to be correct. People are always on the lookout for new apps to improve their productivity and are willing to pay to have it. I didn’t even expect people to be willing to pay, but there is a high willingness to pay.
Life Graph
It is interesting to me that I started on this journey by creating a simple embedding map of my own essays, just because I thought it was cool. There really is no utility to it at all, but some people seem to be interested in the platform just because of that feature alone. Over time, I would like to continue to build this in a way in which it is more interactive and graph memory works correctly, where proper nodes connect to each other and you can dive deeper into the state of your life at different moments in time. Another cool idea is to implement a similar feature to Snapchat of “from your memories 1 year ago.” I no longer use Snapchat, but I still love that feature and love going back in time to reminisce on my past memories with friends.
I struggle to pin down the “why” for why people find this interesting. My goal isn’t really to create a web app here. I want it to be a utility. But if people find this valuable…
The API
We have also built an API capability as it seems there is also significant demand for agentic memory. This space is rapidly evolving, but there are many gaps in the market.
From my last essay, I mentioned that Supermemory was the only memory application for consumers. It now seems that they’ve pivoted to a developer tool with a form of seemingly lightweight, low-latency RAG for agentic memory. I tried using it and wasn’t impressed, still frankly.
There is a lot to do in the memory space. But we can’t do it all and spread ourselves too thin.
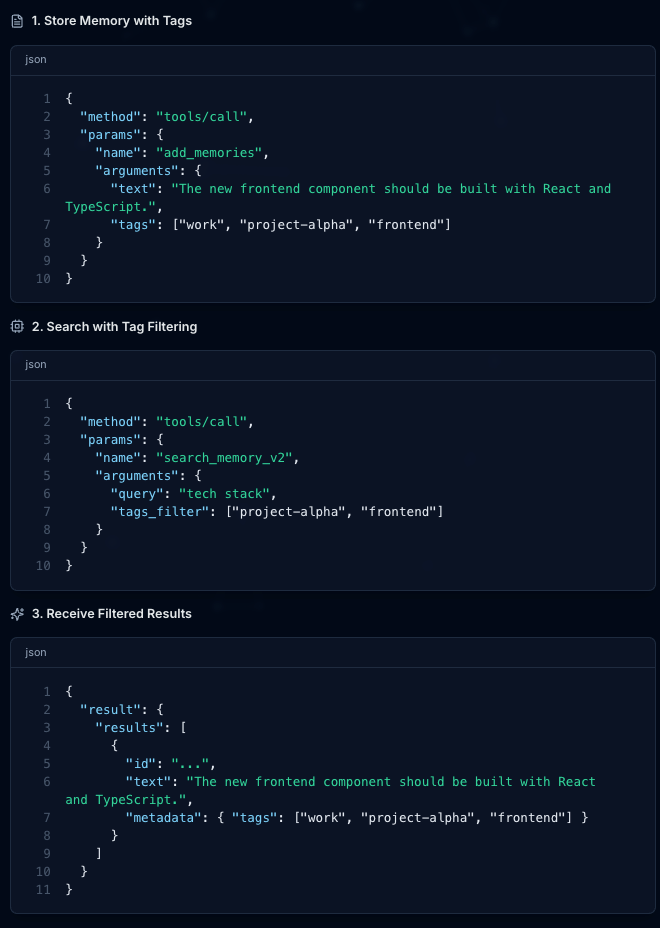
Focusing The Product
As we have built, there is a certain question that has arisen of how narrow do you focus the product. Our product is quite broad right now. And it is that way by design. The nature of a universal memory tool is that it should be universal and it should aggregate context from many parts of your life and be accessible from any of those applications. But the truth is that people really use this mostly in Claude and Cursor. And this is to be expected. There is a power law of tooling that these applications simply dominate the market and most people use these and ChatGPT. We have enabled ChatGPT enterprise to use our memory, but it is only restricted to deep research through their docs (MCP Docs).
The more real reason you need to focus the product that I’m coming around to is not because it is distracting to the user if it’s too complex, it is just really difficult to make something great. A small bug will cost me 2 days, with so many things on our road map. It is entirely different to create something great for 1 person vs 20 different people who all use it very differently.
The microeconomic reason you need to get the narrow version right is because posting on Reddit every day is not sustainable. You need to identify a narrow group of people in which the distribution makes sense. So you need to get the math right so that for every dollar you spend getting people’s attention, the bottom-of-funnel paying users justify it. So that means getting a high-value, great product for a narrow group of people. Once you’ve won that market, then you can think about how you can scale up. Finding the right distribution channels that click is also a hurdle in itself.

The Pivot Inside the Pivot
It does seem like we are going to need to hone in on the “working memory” angle. But I need to talk to users more to understand their pains and desires.
We will make it even easier to use and more effective. We will have a clear path to a pro version that has clear actionability on the path to upgrading and the value it provides.
Alongside this, there are also various features and integrations that are just asked by our customers that we need to look into.
Integrations for Typing Mind
Compatibility with Gemini (not possible right now unfortunately)
Save down Markdown files
We also have major plans for general infrastructure reorganization. We have looked into different technical architectures that closely mirror the human brain.
Lot to do. Excuse the rambling and messiness.