
Introduction
Back from the top. In the first essay, we describe how, even with a crisp problem in hand, it can be difficult to pin down the correct solution. The practical nature of PMF requires coordinating multiple dimensions, such as infrastructure, market headwinds, customer incentives, etc.
In the second essay, we outline how MCP represents a shift towards standardized infrastructure and a need for connecting external context and tooling to our LLMs.
My vision remains firm. Now that machines understand us in such a deep way, it opens the door to perverse possibilities for companies like OpenAI to monetize their understanding of us. It is the responsibility of the open-sourced community to build this in a way that protects individual data rights and ensures sovereignty of individuals in an increasingly centralized world.
In this essay, we will take recent learnings from the market to update our previous “how”. This messy essay is the first leg of a journey of mapping out this new territory so I can get back to building.
Testing and Iterating Across Different Solutions to the Problem
In the first essay, we also described the need to test and iterate. It requires planning from an abstract level, so as to try to condense the problem and solution space into more manageable sizes. Once you have condensed the problem and solution space, then you must work directly with customers to build the ideal solution. There is a dialectical balance you need to strike between removing yourself from society when individually choosing the right general problem to solve and focusing on the specific solution to solve problems directly for customers.
From a high level, it makes perfect sense that models need to have access to our context in order to act on our behalf. This can be thought of as the problem we are aiming to solve in problem space p.
However, it also requires coordination with solution space S(p). There are many angles to solve this problem from, and they take the form of different industry sub-networks, customer personas, and specific practical problems that customers face today.
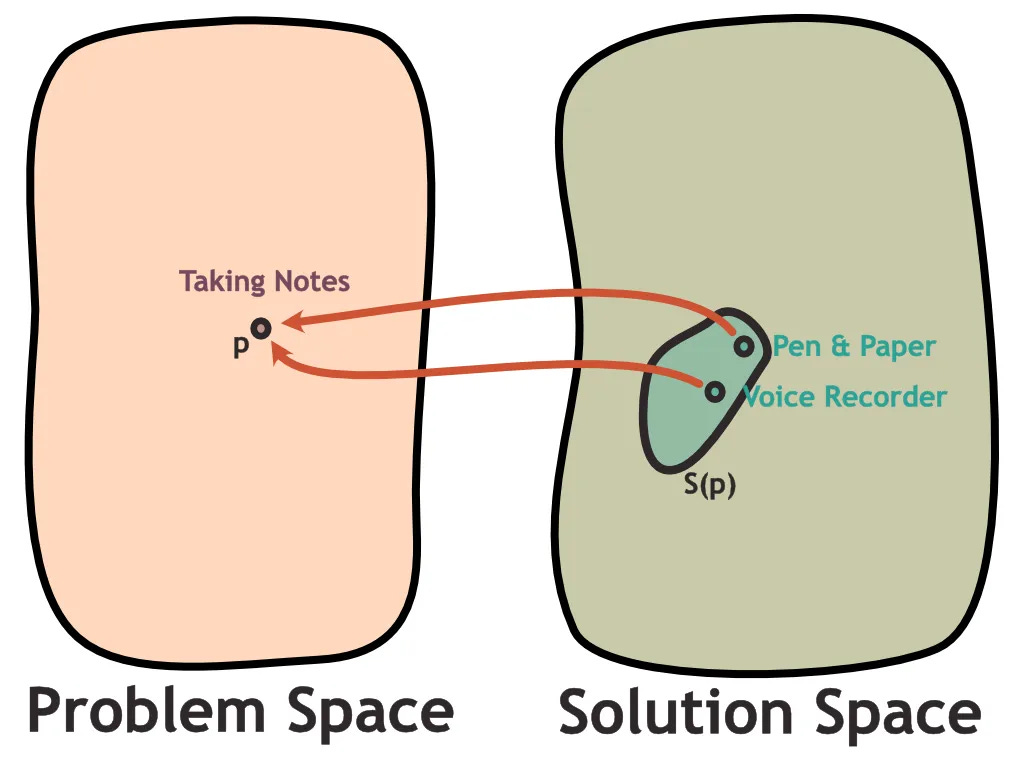
In our example, the point in problem space we are trying to solve is that models don’t have access to individual personal context, so everyone roughly gets the same generic experience.
The points we are examining are different in solution space S(p) on what form this will actually take. Developments around MCP change how we should think about what customer we are ultimately solving for.
High-Level Problem
We came to the realization several months ago that in order for AIs to work with individual humans, they need to understand us. The problem is that even the most intelligent models do not have access to context in our lives to 1) act on our behalf and 2) personalize the experiences to our unique personalities.
Chat-GPT has recently introduced more capabilities in user memory to personalize the experience to the user and remember their preferences and past behaviors. This is where the industry is heading.
Low-Level Solutions
The process of finding the exact solution is a bit more complicated, and it has required testing with different industries and personas. We have learned from our escapade into e-commerce.
Selling has been very difficult. I’ve faced a tension between short-term and long-term. Long-term, you have a vision that you are moving towards, and short-term, it is easier to just pick out an individual customer and solve problems for them. However, these detours often pull you off track, such as building MCP servers, workflow automations, etc. I am not building this company to solve an arbitrary problem dictated by the market, I want to solve the problem of getting models our context to act on our behalf.
In e-commerce, I found it difficult to find customers. I am going to run another experiment focused on another sub-network of developers, with outreach on Reddit. I have found this community to be much more engaged with these questions and solutions.
Changing Course
We are likely going to change course to test another angle, this time focusing on developers in MCP.
I’ve become more of a Redditor than I’d like to admit. But in customer acquisition, you realize that there are different channels that may have different levels of traction. The people who seem to care most about these issues are the nerds, and they reside on Reddit. Reddit is the best place I’ve found that has people interested in similar things. And the world is small there too.
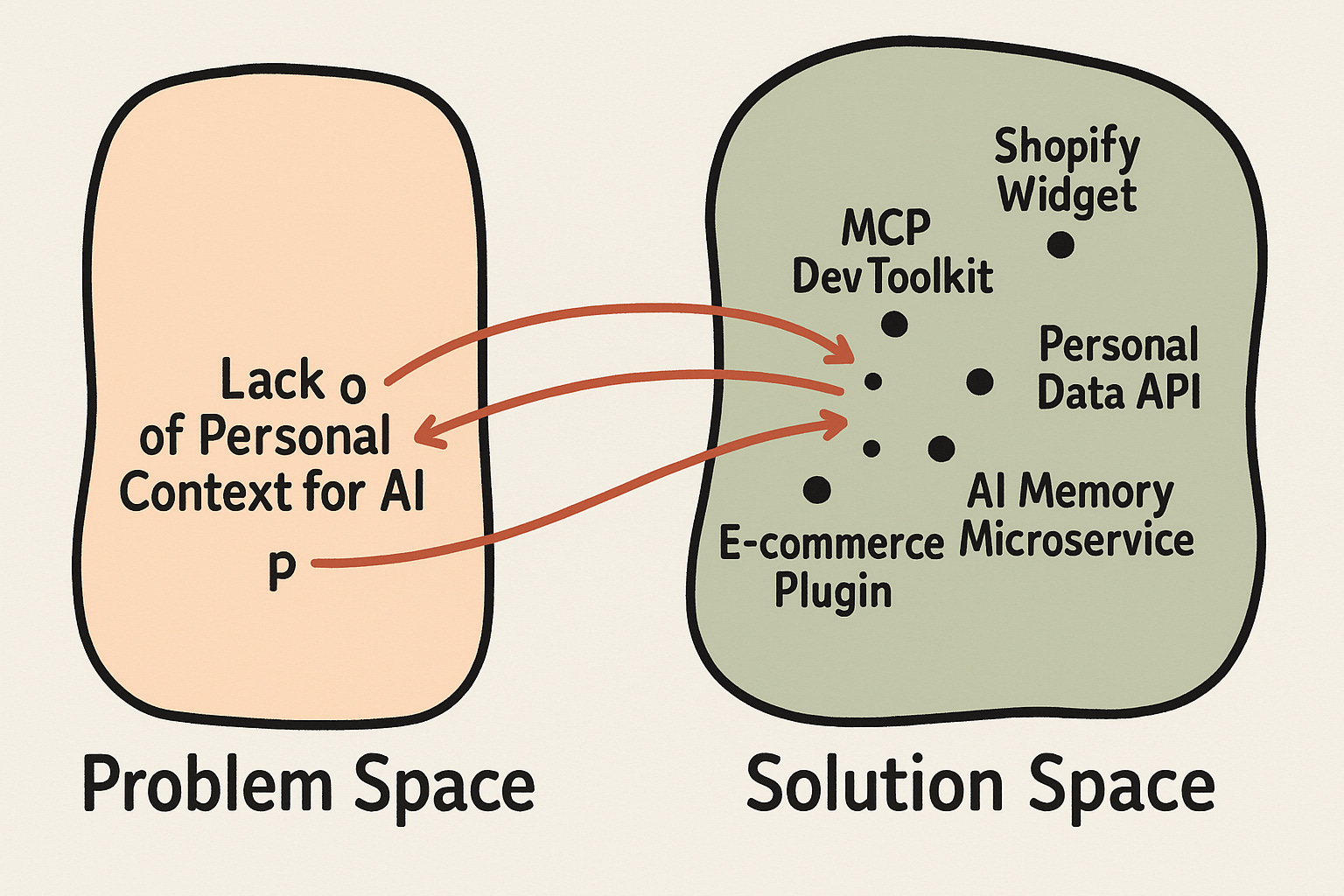
Here is Chat-GPT’s image generation of what I am imagining. It does a pretty good job at showing the different solutions we have tried so far. Let’s shift to another one, B2C Memory.
The Coordination in a Network
You can imagine that the network is composed of individual users and businesses.

You expect that there is a certain data gravity towards the user, connected to a unique UUID. Bootstrapping this context is the difficult part. Is the data tied directly to the user? Or is there a middleware that the data eventually compiles into that can then link into each business? What form does that take?
This was a question that I think I struggled with for some time, and I still do. It makes sense to me that you would have a single memory layer to connect into.
There are many memory solutions that are being built for enterprises where the context is memorized per each unique user. Think of this as a data gravity towards the users but on the side of the businesses.
What I think that MCP tells us is that it’s going to be much closer to the consumers, at least at first. Rather than a trusted steward like Plaid, it is much more likely that the users themselves will connect their context into their applications, either with OpenAI or another party with their context. And then this will connect into businesses. But will it run locally? Will it be an SSE hosted service? Probably SSE.



We also need to think through what the best sources and uses of this data will be. Where are the narrowest, highest-value use cases? Tapping into many sources via integrations and such is non-trivial. How much context do you need?
B2B
Basically, in initial outreach, I was forced to decide whether to focus my efforts on businesses or consumers. Intuition and conventional wisdom told me that I should focus on B2B.
There is a chicken-and-egg problem. In a network, you need to bootstrap the initial connections. I figured that since the businesses are incentivized to understand their users better, they would be incentivized to build out ways to get this data. There is possibly a market here, and there are competitors that serve as some validation of this, but getting integrations with meaningful data from off-site sources is difficult.
There is possibly a route where you can build a “Clearbit for E-Commerce.” This actually seems like a relatively valid path. I learned from the market that these stores already are sitting on goldmines of data that they don’t know how to use, so a way to further enrich that dataset could have a path towards (1) making existing data more valuable and then (2) incentivizing them to join the network to ingrain that into their infrastructure for greater personalization. Basically, getting those integrations set up and their value is non-trivial.
And the more intangible reason that it feels like e-commerce sucks is it’s hyper-focused on conversions and has little technological interest or imagination.
B2B - Memory
However, there are many applications that are springing up reflecting the need to create a memory layer for businesses: Zep, Mem0, Cognee, etc. I only see Supermemory.ai for consumers. But why? Chat-GPT has memory–what about creating that for B2C?
B2C
I didn’t create this for B2C because most are not technical. And I don’t know if I was even wrong. But I do think the core reassessment here is that as marketplaces turn MCP Servers into one-click installations, it opens up tooling for your average Joe or the non-technical user. We are seeing this in n8n, where less technical people can now build workflows, and I have spoken to people building memory that say that this has accelerated adoption. But I still don’t see any good applications.
I have met some people online that are already crowbarring B2B memory solutions such as Zep into personal memory agents.
Maybe rest assured, we can see that Supermemory.ai was Product Hunt’s #1 Product of the Day and has nearly 10,000 stars on GitHub and has been steadily growing.

Just from first glance, this project has immense community support, but using it as a non-technical person is still difficult and frankly I didn’t really like that:
The integrations were limited (I don’t use Obsidian and the Twitter bookmarks were limited)
It tries to memorize everything, such as what you’ve browsed, which isn’t really relevant to “understanding” you.
There are also other hardwares, such as Limitless and Omi and other glasses that I’ve come across that aim to memorize things about your life and enable personalization in the age of AI.

My instincts tell me that the focus should still be on understanding, but maybe I am just delusional. Perhaps even proper context and memory, when correctly called in a prompt, simply converges on understanding. I’m running out of steam here and it makes sense for me to just talk to users of these technologies and see how to improve them for the customers’ use cases.
Connecting the Network
It really doesn’t feel like the industry is ready to connect into context. The businesses don’t have the infrastructure to support it yet, and there are no middleware layers (like Plaid) that exist and have hit sub-network density yet. OpenAI has publicly stated that they want to build a “sign in with OpenAI” feature. This not only feels like it will end in perverse, Orwellian ways, but OpenAI doesn’t have access to context outside of its application.
Previous What, Why, and How
What: universal gas station for user understanding.
Why: in order for AI applications to act on our behalf, they need to have access to our context.
How: wedging in as a B2B Context + Personalization in e-commerce.
The result of this experiment was that it didn’t quite stick, even though there are competitors building similar things, it feels like it might be at least a temporary dead end. The gravity leans into the user and their LLMs.
New What, Why, and How
What: personal memory layer, B2C memory layer.
Why: in order for AI applications to act on our behalf, they need to have access to our context.
How: Create a better MCP memory tool for technical users, preparing for consumer adoption.
Jean is a personal memory layer designed for technically adept users. Jean aggregates context from user-permitted sources, employs intelligent retrieval, and exposes this context via standardized interfaces, initially leveraging the Model Context Protocol (MCP).
Hypothesis: current memory for users is limited to the Chat-GPT platform. By building a more open and trusted memory across applications, we can improve personalization and contextually relevant responses to the user.
Literature Review and Inspiration From the Market
Prior work
General Personal Embeddings: Deep representation learning allows models to understand complex concepts, including human thought patterns expressed through data (text, code, etc.). There are limitations that make embeddings a poor use case here but the thesis for a universal, trusted layer still stands in need of relevant context delivered at inference time. This aligns with the rise of RAG and now, more sophisticated context protocols.
As infrastructure in the industry is sorted out, MCP specifically lowers the barrier for providing external context, making a product like Jean more feasible and integrable. We expect this trend to continue for increasing ease in user adoption.
Review of Existing Solutions & The Gap
MCP.run in the pure sense that someone told me it’s relevant
Chat-GPT - Obvious memory
Claude - barebones knowledge graph for Claude chats
Letta (formerly memGPT)
etc.
Interestingly much of this is open-sourced, and I’m sure that there is much to do here. I haven’t dove deep into any of these yet but many feel focused on B2B and Supermemory felt like it was lacking in ways that I would want for my own personal use cases.
The Identified Gap: The lack of a robust, persistent, user-controlled memory layer that aggregates deep personal context from diverse sources and integrates seamlessly with the emerging ecosystem of AI agents and tools via standards like MCP.
Standardized Interface: Exposes context retrieval functionality via an MCP Server. This is the key integration point for the initial test. The server would offer resources/tools like
pull_relevant_context(query: string, sources: list[string] = None, top_k: int = 5) -> list[ContextChunk].Methodology
Without going too deep into the methodology, we are just going to build this damn thing and try to build it out for users in the process. There’s a lot of good open sourced code out there, so that will come in handy when putting this all together.
Targeting technical people on Reddit.
I want to see if we can make Supermemory that is better at personalization and memory and incredibly simple to set up. We will need to map out the sources and uses of user context again as well.
Conclusion
Further, there are viable questions around business models here and how you monetize a free memory layer. I think the end-state must be built in a way that protects individual data sovereignty and eventually building B2B edges for users who choose to do this.
Reach out if you are interested in contributing to this work: jonathan@jeantechnologies.com